TL;DR
A guide to the 7 best Reddit scrapers for extracting posts, comments, and community data quickly and efficiently in 2026.
- ScrapeGraphAI is the top choice — AI-powered extraction using plain English prompts
- Apify has pre-built Reddit actors — no coding required with a scalable cloud platform
- Tools for all skill levels — both developer-friendly APIs and no-code options available
- Reddit data is a goldmine — posts and comments on every topic for research and insights
- Free plans to start — most tools offer a $0 tier for initial scraping needs
You know that feeling when you're trying to find specific information on Reddit?
The platform is a goldmine of data, with posts and comments on every topic imaginable.
But digging through it all manually is a huge pain.
You can get lost in an endless sea of threads and still not find what you need.
It can take hours of your valuable time.
The good news? There's a simple solution.
You can use a Reddit scraper to do the heavy lifting for you.
In this article, we'll show you the 7 best Reddit scrapers available in 2025.
These tools are fast, easy to use, and will help you get the data you want without the headache.
What is the Best Reddit Scraper?
Choosing the best Reddit scraper depends on your specific needs.
Are you a developer who likes to code?
Or do you prefer a simple, no-code tool? Our list has something for everyone.
We've broken down the best options to help you decide which one is right for you.
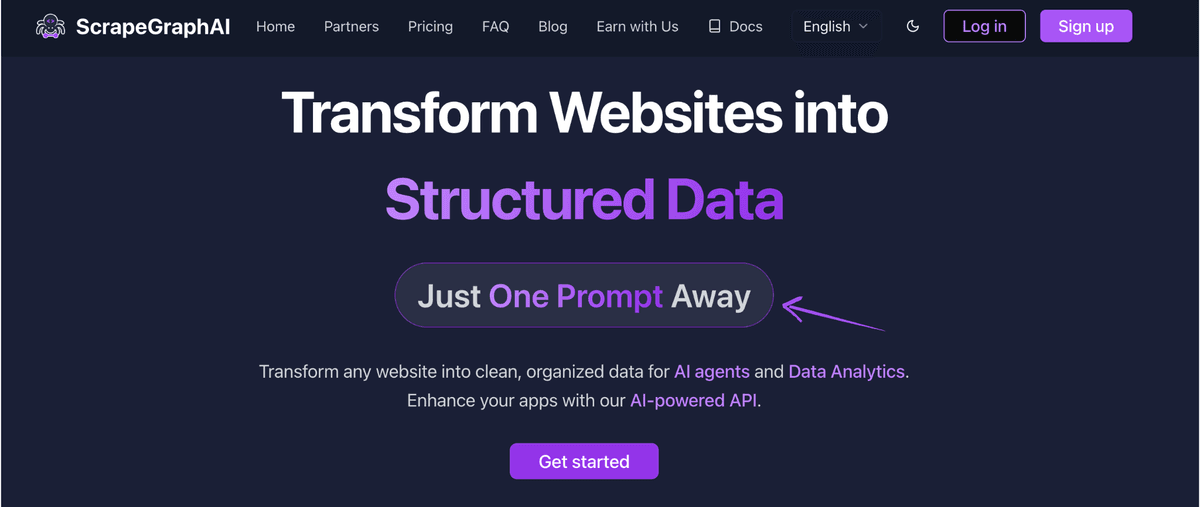
1. ScrapeGraphAI
This tool uses artificial intelligence to make scraping simple.
You tell it what you want in plain English, and it handles the rest for you.
It's a game-changer.
Key Benefits
- Intelligent identification of data points.
- Automatic handling of website changes.
- Easy integration with other tools.
- Quick setup in just a few minutes.
Pricing
- Free: $0/month.
- Starter: $20/month.
- Growth: $100/month.
- Pro: $500/month.
- Enterprise: Custom Pricing
Pros & Cons
Here's what I think about ScrapeGraphAI:
Pros:
-
It's super easy to use.
-
AI makes it very accurate.
-
Handles website changes well.
-
Good value for the money. Cons:
-
Fewer integrations than some.
-
Advanced features need learning.
Rating
Rating: 9/10.
ScrapeGraphAI is really smart and accurate, which saves a lot of time. The price is fair for what it offers, and the guarantee is a nice touch. It loses a few points because the integrations are a bit limited, and getting the most out of the advanced stuff takes some effort.
2. Apify
Apify is a platform with pre-built "Actors" for specific sites.
Their Reddit Scraper is a great option.
It's a very reliable and powerful tool that can handle complex scraping jobs without you writing any code.

Key Benefits
- A wide range of pre-built scraping tools (actors).
- Scalable cloud platform for running tasks.
- APIs for custom integrations.
- Options for building your actors.
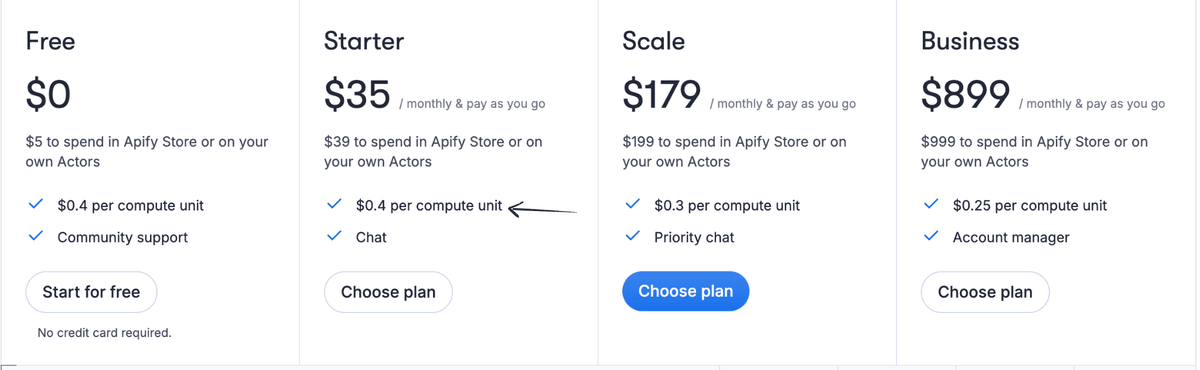
Pricing
- Free: $0/month.
- Starter: $35/month.
- Scale: $179/month.
- Business: $899/month.
Pros & Cons
Here's my take on Apify:
Pros:
-
Huge selection of ready-made tools.
-
Very scalable cloud infrastructure.
-
Good for developers with its APIs.
-
The free tier is great for trying things out. Cons:
-
It can be a little bit complex sometimes.
-
Costs can add up with heavy usage.
-
The quality of actors can vary.
Rating
Rating: 8.5/10.
Apify is a powerful and flexible platform with a lot to offer, especially for developers and those with more complex needs. However, the sheer number of options and the usage-based pricing might be a bit daunting for beginners.
3. ScrapingBee
This is an API-based service that takes care of common scraping problems.
It handles headless browsers and proxy rotation automatically, letting you focus on the data you need to collect from Reddit.
Key Benefits
- Handling of proxies and CAPTCHAs.
- JavaScript rendering for dynamic sites.
- Simple API for easy integration.
- Geolocation targeting for specific data.
Pricing
- Freelance: $49/month.
- Startup: $99/month.
- Business: $249/month.
- Business+: $599/month.

Pros & Cons
Here's what I think about ScrapingBee:
Pros:
-
Great at avoiding blocks and captchas.
-
Handles JavaScript websites well.
-
Simple API is easy to use.
-
Good for reliable data delivery. Cons:
-
Less control over the scraping process.
-
It can become costly for large volumes.
-
Fewer visual tools for non-coders.
Rating
Rating: 8/10.
ScrapingBee is well known for its fast scraping. If you're tired of getting blocked while scraping, this service is excellent. It handles the technical headaches for you. However, it can get expensive for large-scale needs, and you have less direct control over the scraping logic.
4. Browse AI
Browse AI is a no-code tool that uses pre-built robots to scrape data from specific websites, including Reddit.
It's perfect for non-technical users who want to monitor trends or extract data without any manual work.
Key Benefits
- No-code, visual data extraction.
- Ability to monitor website changes.
- Integration with popular automation tools.
- Pre-built robots for common use cases.
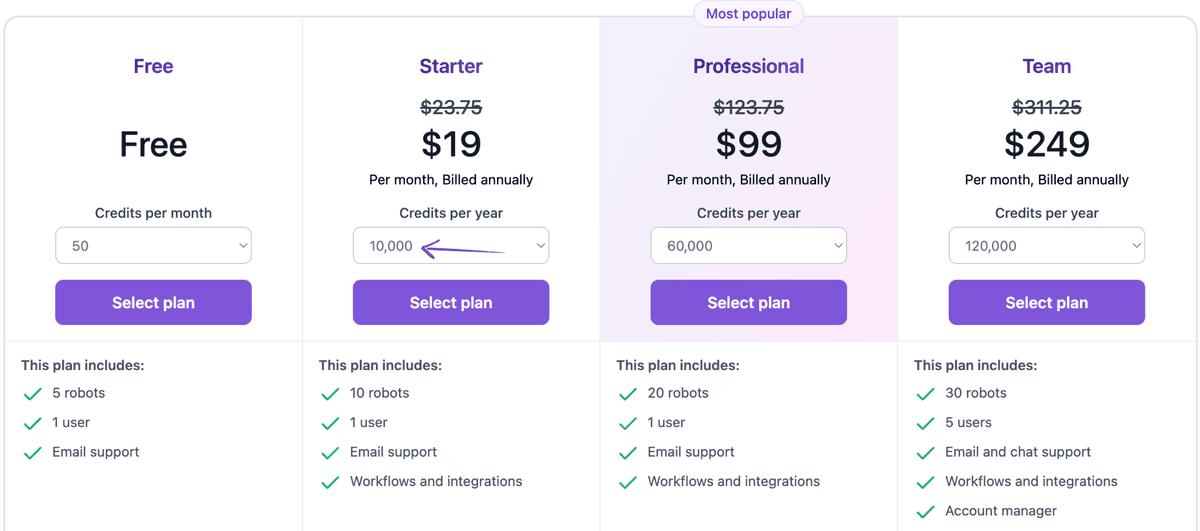
Pricing
- Free: $0/month.
- Starter: $19/month.
- Professional: $99/month.
- Team: $249/month.
Pros & Cons
Here are my thoughts on Browse AI:
Pros:
-
Extremely easy to get started.
-
No coding knowledge needed at all.
-
Monitoring changes is a great feature.
-
Integrates with many other tools. Cons:
-
It can become expensive as you scale.
-
Might not handle very complex sites.
-
Relies heavily on visual recognition.
Rating
Rating: 7.5/10.
Browse AI's ease of use is a huge advantage, especially for non-technical users. The ability to monitor changes is also very valuable. However, the cost can add up, and it might not be the best for the most intricate website structures.
5. Octoparse
Octoparse is a visual web scraper.
You can use it to build your own scraper with a point-and-click interface.
It also has templates for many popular sites, including Reddit.
Key Benefits
- Visual point-and-click interface.
- Cloud-based scraping capabilities.
- Scheduled scraping and automation.
- Ability to handle complex websites.
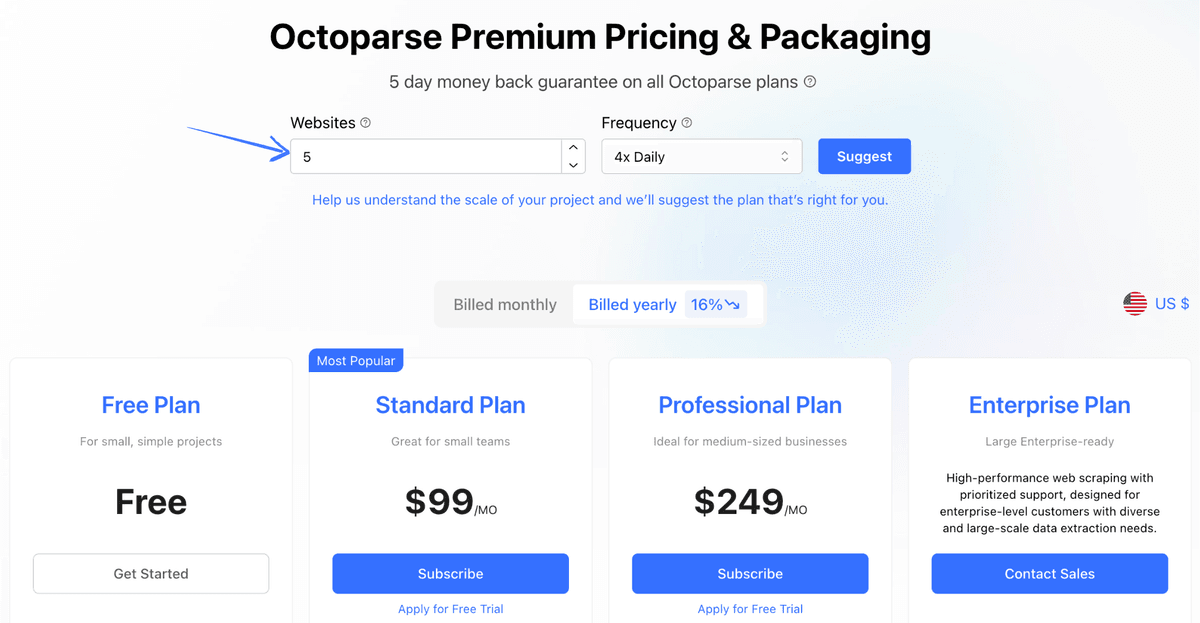
Pricing
- Free: $0/month.
- Standard: $99/month.
- Professional: $249/month.
- Enterprise: Custom Pricing
Pros & Cons
Here's my take on Octoparse:
Pros:
-
Very user-friendly interface.
-
Great for non-coders like me.
-
Cloud scraping is super handy.
-
Scheduling is a big time-saver. Cons:
-
It can get pricey for teams.
-
Cloud server limits exist.
-
Sometimes struggles with very dynamic sites.
Rating
Rating: 7/10.
Octoparse is fantastic for people who don't want to code, and the cloud features are a real plus. However, the cost for teams can add up, and it's not always perfect with super complex websites. The lack of a specific warranty is also a minor drawback.
6. Firecrawl
Firecrawl is a web data API designed for AI applications.
It can crawl and scrape any Reddit URL, converting the content into clean, structured data ready for use by large language models.

Key Benefits
- High-performance crawling engine.
- Real-time data delivery options.
- Scalable architecture for large projects.
- Integration with popular cloud platforms.
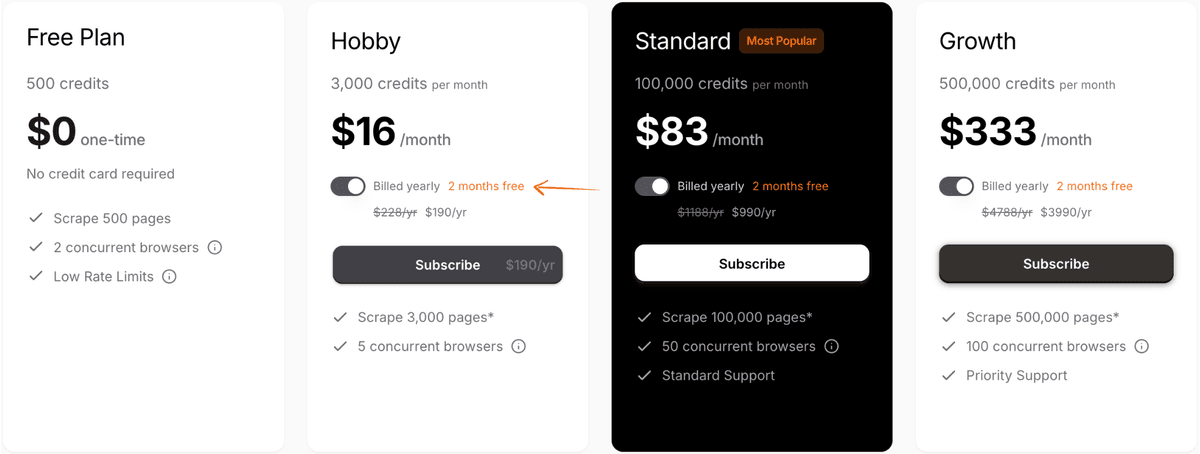
Pricing
- Free: $0/month.
- Hobby: $16/month.
- Standard: $83/month.
- Growth: $333/month.
Pros & Cons
Here's what I think about Firecrawl:
Pros:
-
Incredibly fast for big jobs.
-
Designed for large-scale scraping.
-
Real-time data is very useful.
-
Integrates well with cloud services. Cons:
-
It might be overkill for small tasks.
-
Pricing can be less transparent upfront.
-
Possibly requires more technical knowledge.
Rating
Rating: 7/10.
Firecrawl is a strong contender if you need to scrape massive amounts of data quickly. However, it might be too much for smaller projects, and getting clear pricing information can take an extra step.
7. ScrapeStorm
ScrapeStorm is an AI-powered desktop application.
It's a visual tool that makes scraping easy.
You enter the URL, and it automatically identifies the data you might want to scrape.
Key Benefits
- Fully automated scraping process.
- Intelligent pattern recognition.
- Support for various data export formats.
- Ability to handle complex website structures.
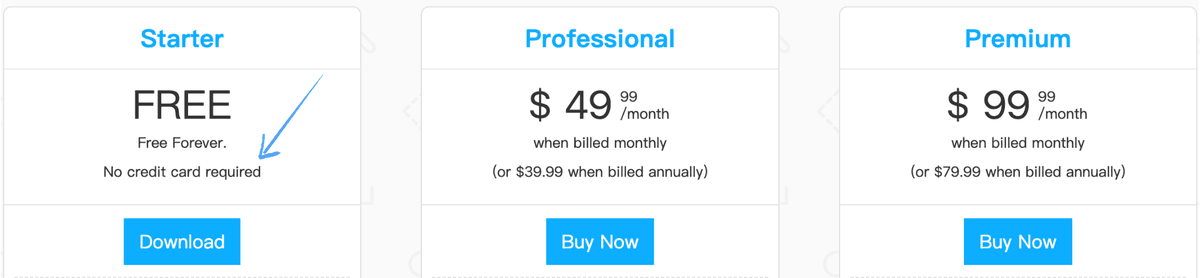
Pricing
- Free: $0/month.
- Professional: $49.99/month.
- Premium: $99.99/month.
Pros & Cons
Here are my thoughts on ScrapeStorm:
Pros:
-
Automation is really impressive.
-
It handles complex sites well.
-
Lots of tasks on the basic plan.
-
Good for users with less experience. Cons:
-
Less control over specific details.
-
Advanced customization can be tricky.
-
The interface might feel different initially.
Rating
Rating: 6.5/10.
ScrapeStorm's automation is a big plus, especially if you're dealing with many different websites. It's also quite capable of complex structures. However, the trade-off for automation is less fine-grained control, and the interface might take a little getting used to.
What to Look for in a Reddit Scraper?
When you're looking for the right tool, it's easy to get overwhelmed by all the choices.
Here's a quick list of what matters most when choosing a Reddit scraper:
- Ease of Use: Do you need to be a coding expert, or is it a simple point-and-click tool? Look for a scraper that matches your skill level.
- Data Quality & Formats: The best tools provide clean, structured data with minimal manual cleanup. Ensure the scraper can export data in formats you can actually use, such as CSV or JSON.
- Anti-Scraping Measures: Reddit is designed to block bots. A good scraper can handle dynamic content loading, IP rotation, and CAPTCHA to ensure your job runs smoothly without getting blocked.
- Speed & Scalability: Consider how fast the tool can scrape data and if it can handle large-scale projects. If you need to collect a lot of data, look for a tool that can scale with your needs.
- Integration: Can you connect the scraper with other tools you use? Look for APIs or direct integrations that make your workflow easier.
How can a Reddit Scraper Benefit You?
A Reddit scraper is a great tool for anyone who needs a lot of data quickly.
Manually browsing Reddit pages and copying information is slow and frustrating.
Using a Reddit scraper automates this process.
It helps you get valuable scraped Reddit data for your business or research without the headache of going through every single Reddit post yourself.
This saves you a ton of time and effort.
You can use the Reddit data to do things like sentiment analysis on a specific topic.
You can see how people really feel about a product or brand by looking at what they say in a subreddit post.
A good Reddit scraper will handle the technical stuff for you, so you don't get blocked by network security.
The tool works by following a post URL and collecting important post details, like comments, upvotes, and links.
It gives you the raw information, which is a big help.
Even though the Reddit API is useful, a Reddit scraping tool can sometimes get even more data, which is a huge bonus.
Buyers Guide
During our research to find the best web scraping tools for Reddit, we looked beyond just features.
We sought tools that are both easy to use and powerful enough for complex tasks.
Here's a breakdown of our method.
- Ease of Use: We evaluated whether prior knowledge of Python or JavaScript is required to use the tool. We checked for visual builders and simple interfaces. We even watched YouTube video tutorials to see how straightforward they were for a beginner.
- Compliance with Reddit's Rules: We ensured each tool could respect Reddit's terms. This means it can handle scraping publicly available data without causing issues. We looked for features that prevent you from being blocked by mistake and how to file a ticket if you are.
- Features and Data Output: We focused on tools that provide more data than just the basic response from a single page. We looked for tools that could get full details from a post URL, including upvotes and all details. We also checked if you could collect from multiple subreddits at once, and if you could use a developer token or your own reddit account.
- Ethical Recommendations: We considered tools that are transparent about their web scraping method and provide clear guidelines. We looked for information on how to handle requests and what to do if you get an error message or need to log something. We ensured the tools are designed to scrape subreddits, not just HTML, and that they use a secure HTTPS protocol.
- Support & Community: We evaluated the level of support offered. We sought a straightforward method for creating a file to store the scraped data, importing it into other software, and finding a community for feedback. We even searched for each tool to see what people were saying. We hope this gives you all the details on our process. This is the research method and example we used.
Wrapping Up
Finding the right Reddit scraper can change the way you work.
Instead of manually looking for top posts or the right subreddit, these tools do the hard work.
We showed you some of the best tools, from powerful no-code solutions to those that require a little Python code.
It's important to remember to be careful.
You can easily get blocked by mistake and have to file a ticket.
Also, make sure you don't break Reddit's terms.
Using a good tool means you don't have to worry about getting a Reddit account or using a developer token.
You can easily create bookmarks for the data you find.
Our research shows that the right tool saves time and gets you better results.
Frequently Asked Questions
Can I get blocked by Reddit for scraping?
Yes. Reddit can block your IP address if it detects unusual activity. If you are blocked by mistake, you might be able to file a ticket with their support. You should always respect their terms to avoid this.
Do I need to use my Reddit account to scrape data?
Not always. You can access public information without one. However, some advanced scrapers may require you to use your developer token or your Reddit account for full functionality, especially if you want to get more data than what is publicly available.
What kind of data can I get with a Reddit scraper?
You can collect a summary of post details, a username, image links, and track specific keywords. You can also scroll through threads to get all comments and find the top posts on a subreddit.
Can a scraper handle dynamic content?
Yes. A good scraper can continue to collect data even when a page loads more content as you scroll down. This is a crucial function for modern websites.
What's the difference between a scraper and the Reddit API?
A scraper can sometimes get more data by bypassing some of the Reddit API's limits, though this is not always recommended. The API is a specific way to access data with rules you must respect, and often requires you to use your developer token.
Related Resources
Want to learn more about web scraping and Reddit data extraction? Explore these guides:
- Traditional vs AI Web Scraping - Compare different scraping approaches
- Web Scraping Without Proxies - Understand when you might not need proxies
- JavaScript Site Scraping - Learn how to handle dynamic content These resources will help you master web scraping and choose the right tools for your Reddit data extraction projects.