Best Overall: ScrapeGraphAI
AI-powered scraping with a simple API — no robots to record, no visual training required. Extract structured data from any website using natural language prompts. Plans start at just $20/month with a generous free tier.
Best Value: Apify
With $5 in monthly free credit and paid plans from $35, Apify's marketplace of pre-built "Actors" covers hundreds of use cases out of the box. Great for teams that need variety without custom code.
Most Features: Octoparse
Octoparse packs an AI assistant, hundreds of templates, cloud scheduling, and OpenAPI support into plans starting at $99/month — a strong no-code option for non-technical teams.
Browse AI is a solid no-code scraping tool, but it comes with real limitations: visual-recording robots break when websites change, pricing jumps steeply at scale, and there's no developer API for custom pipelines.
If you've hit those walls, you're in the right place.
In this article, we cover the 7 best Browse AI alternatives for web scraping and automation in 2026.
What is Browse AI?
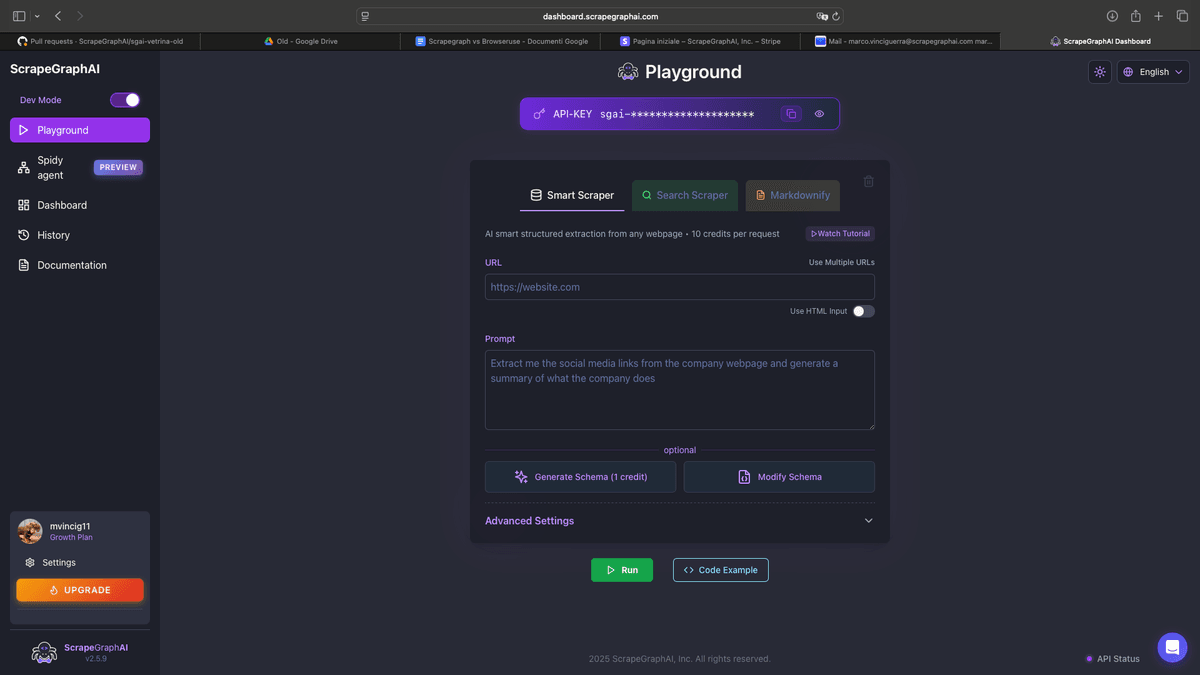
Browse AI is a no-code web scraping and monitoring platform launched in 2020. Users train "robots" by recording actions in a browser — clicking, scrolling, and pointing at the data they want. Those robots then run on a schedule and extract or monitor data automatically.
It's popular with non-technical users who need quick wins on simple monitoring tasks. But it has clear weaknesses:
- Recording is fragile — website redesigns break robots silently
- Expensive at scale — robot runs are credit-limited and costs add up fast
- No developer-friendly API for schema-based or programmatic extraction
- Limited AI — no natural language prompts or automatic adaptation
If any of these resonate, read on.
What Are the Best Browse AI Alternatives?
We evaluated tools based on ease of use, AI capabilities, pricing transparency, developer experience, and reliability at scale. Here are our top picks.
1. ScrapeGraphAI

ScrapeGraphAI is an AI-powered scraping API that extracts structured data from any website using natural language prompts — no recording, no XPath selectors, no fragile CSS rules. You describe what you want, and it figures out the rest.
Unlike Browse AI's robot model, ScrapeGraphAI automatically adapts to website structure changes. It supports custom Pydantic schemas for type-safe output and integrates natively with LangChain, LangGraph, and other AI frameworks.
Key Benefits
- Natural language extraction — describe data in plain English, get structured JSON back
- Schema-based output — define Pydantic models for guaranteed type safety
- No visual training — works on any website immediately, no robot setup
- AI framework integration — plug into LangChain, LangGraph, CrewAI
- Python & JavaScript SDKs with full API access
How to Use ScrapeGraphAI
from scrapegraph_py import ScrapeGraphAI
sgai = ScrapeGraphAI() # uses SGAI_API_KEY env var
# Simple extraction with a prompt
response = sgai.extract(
url="https://example.com/products",
prompt="Extract all product names, prices, and availability"
)
print(response.data.json_data)For structured, type-safe output using Pydantic schemas:
from pydantic import BaseModel, Field
from typing import List
from scrapegraph_py import ScrapeGraphAI
class Product(BaseModel):
name: str = Field(description="Product name")
price: float = Field(description="Price in USD")
in_stock: bool = Field(description="Whether the item is in stock")
class ProductList(BaseModel):
products: List[Product]
sgai = ScrapeGraphAI() # uses SGAI_API_KEY env var
response = sgai.extract(
url="https://example.com/products",
prompt="Extract all products from this page",
schema=ProductList.model_json_schema(),
)
for product in (response.data.json_data or {}).get('products', []):
print(f"{product['name']} — ${product['price']}")
Pricing
- Free: $0/month
- Starter: $20/month
- Growth: $100/month
- Pro: $500/month
- Enterprise: Custom
Pros & Cons
Pros:
- Works on any website without training or recording
- AI adapts automatically when websites change
- Excellent developer experience with SDKs and schema support
- Most affordable starting price among AI scrapers
- Native AI agent and LLM framework integration Cons:
- Requires basic coding knowledge to get the most out of it
- Not a no-code point-and-click tool
Rating
9.5/10 — The best all-around Browse AI alternative for developers and teams that need reliable, AI-powered extraction without the fragility of recorded robots.
2. Apify

Apify is a cloud scraping platform with a marketplace of 1,500+ pre-built "Actors" — ready-to-run scrapers for Amazon, LinkedIn, Instagram, Google Maps, and hundreds of other sites. You can also build and publish your own Actors.
It's a strong alternative for teams that want off-the-shelf solutions without writing scraping logic from scratch.
Key Benefits
- 1,500+ pre-built Actors covering popular platforms
- Cloud infrastructure with scaling, proxies, and result storage built in
- Apify SDK for building custom scrapers in JavaScript/TypeScript
- Integrates with Zapier, Make, and other automation tools
Pricing
- Free: $5 credit/month
- Starter: $35/month
- Scale: $179/month
- Business: $899/month
Pros & Cons
Pros:
- Huge marketplace of ready-to-use scrapers
- Great for non-coders who need specific platform scrapers
- Strong cloud infrastructure for running tasks at scale
- Active developer community Cons:
- Actor quality varies — some are poorly maintained
- Costs rise quickly with heavy usage
- Less flexibility than building a custom scraper for unusual sites
Rating
8/10 — Ideal if a pre-built Actor already covers your use case. Less ideal for custom or dynamic extraction needs.
3. Octoparse
Octoparse is a desktop and cloud-based no-code scraper with a visual point-and-click interface. You build extraction workflows by clicking on page elements, and Octoparse handles the rest — including scheduling, cloud execution, and export.
It's one of the most fully-featured no-code alternatives to Browse AI, with an AI-powered mode that auto-detects data patterns on a page.
Key Benefits
- Visual drag-and-drop workflow builder
- AI-powered auto-detection of tables and lists
- Cloud scheduling and parallel task execution
- Hundreds of pre-built templates for common sites
- Export to CSV, Excel, JSON, Google Sheets, databases
Pricing
- Free: $0/month (limited)
- Standard: $99/month
- Professional: $249/month
- Enterprise: Custom
Pros & Cons
Pros:
- No coding required — great for non-technical users
- AI auto-detection speeds up setup significantly
- Strong template library reduces time to first result
- Cloud execution means no need to leave your computer running Cons:
- More expensive than developer-API tools for equivalent data volumes
- Complex JavaScript-heavy sites can still trip it up
- Desktop app can feel clunky compared to browser-based tools
Rating
8/10 — The most feature-complete no-code alternative. A direct upgrade from Browse AI if you want to stay no-code but need more power and reliability.
4. ScrapingBee
ScrapingBee is a developer-focused scraping API that handles all the hard parts of modern scraping: rotating proxies, CAPTCHA solving, JavaScript rendering, and headless browser execution. You send a URL, and it sends back clean HTML or rendered page content.
It's less of a Browse AI replacement and more of a scraping infrastructure layer — useful when you want to write your own extraction logic but don't want to manage proxies and anti-bot systems.
Key Benefits
- Automatic proxy rotation and CAPTCHA solving
- JavaScript rendering with Chromium headless browser
- Geolocation targeting for localized content
- Simple REST API with minimal setup
- Stealth mode for difficult anti-bot sites
Pricing
- Freelance: $49/month (150,000 API credits)
- Startup: $99/month (500,000 API credits)
- Business: $249/month (2,500,000 API credits)
- Business+: $599/month
Pros & Cons
Pros:
- Excellent at bypassing anti-bot measures
- Handles JavaScript-heavy SPAs reliably
- Simple API that integrates with any language or framework
- No need to maintain your own proxy infrastructure Cons:
- No built-in data extraction — you still parse the HTML yourself
- Can get expensive at high volume
- Not suitable for non-technical users
Rating
7.5/10 — Best for developers who need reliable HTML delivery but want to handle extraction themselves.
5. Firecrawl

Firecrawl is an LLM-focused web scraping API that converts any webpage into clean Markdown or structured JSON — optimized for feeding AI models and RAG pipelines. It supports full site crawling, not just single-page extraction.
If you're building AI applications that need clean, LLM-ready web content, Firecrawl is purpose-built for that use case.
Key Benefits
- Converts pages to clean Markdown automatically
- Full website crawling with sitemap support
- Structured extraction with LLM-powered schemas
- Webhooks for real-time data delivery
- Native integrations with LangChain, LlamaIndex
Pricing
- Free: $0/month (500 pages)
- Hobby: $16/month
- Standard: $83/month
- Growth: $333/month
Pros & Cons
Pros:
- Excellent Markdown output quality for AI/LLM workflows
- Fast and scalable crawling architecture
- Simple API that's easy to get started with
- Good free tier for testing Cons:
- Less control over fine-grained extraction than schema-based tools
- Priced per page-crawl, which adds up for large sites
- Not ideal for non-developer users
Rating
7.5/10 — A strong choice for AI and LLM applications that need clean web content at scale.
6. Zyte
Zyte (formerly Scrapinghub) is an enterprise-grade web scraping platform with over a decade of experience. It offers managed scraping services, a smart proxy network (Zyte Smart Proxy Manager), and an AI-powered automatic extraction API.
For large-scale, mission-critical scraping operations, Zyte provides the infrastructure and SLAs that enterprises need.
Key Benefits
- AI-powered automatic data extraction (no CSS selectors needed)
- Zyte Smart Proxy Manager with 100M+ IPs
- Managed scraping service with human oversight option
- Support for Scrapy framework projects
- Enterprise SLAs and dedicated support
Pricing
- Pay-as-you-go from $0 (Zyte API)
- Managed plans: Custom pricing
- Smart Proxy Manager: From $29/month
Pros & Cons
Pros:
- Battle-tested infrastructure for large-scale operations
- Industry-leading proxy network
- AI extraction that handles website changes automatically
- Strong enterprise support and SLAs Cons:
- Complex pricing model can be hard to estimate upfront
- Overkill and expensive for small to medium projects
- Steeper learning curve than simpler tools
Rating
7.5/10 — The go-to for enterprise teams running scraping operations at serious scale who need SLA-backed reliability.
7. ParseHub
ParseHub is a free desktop application for building web scrapers visually, similar to Browse AI and Octoparse. It uses machine learning to understand and navigate website structures, making it capable of handling pagination, dropdowns, login-protected pages, and JavaScript-rendered content.
It's a strong free alternative for individuals and small teams.
Key Benefits
- Free desktop app with a generous free tier
- ML-powered navigation for complex multi-page sites
- Handles JavaScript, AJAX, dropdowns, and logins
- Export to JSON, CSV, Excel, or via API
- Supports scheduled cloud runs on paid plans
Pricing
- Free: $0/month (5 projects, limited)
- Standard: $189/month
- Professional: $599/month
Pros & Cons
Pros:
- Powerful free tier for personal projects
- Handles complex multi-step navigation
- No coding required
- Good for login-protected pages Cons:
- Paid plans are expensive compared to competitors
- Desktop app is less convenient than cloud-native tools
- Slower extraction speed than API-based solutions
- UI can feel dated compared to newer tools
Rating
7/10 — A solid free option for individuals. For teams or production workloads, the pricing is hard to justify versus alternatives.
Feature Comparison: Browse AI vs Top Alternatives
| Tool | Best For | AI-Powered | No-Code | Pricing From | Developer API |
|---|---|---|---|---|---|
| ScrapeGraphAI | AI extraction, custom pipelines | ⭐⭐⭐⭐⭐ | No | $20/month | Yes |
| Browse AI | Simple monitoring, no-code | ⭐⭐ | Yes | $19/month | Limited |
| Apify | Pre-built scrapers, marketplace | ⭐⭐⭐ | Partial | $35/month | Yes |
| Octoparse | No-code power users | ⭐⭐⭐ | Yes | $99/month | Yes |
| ScrapingBee | Anti-bot, proxy infrastructure | ⭐⭐ | No | $49/month | Yes |
| Firecrawl | LLM/AI content pipelines | ⭐⭐⭐⭐ | No | $16/month | Yes |
| Zyte | Enterprise scale | ⭐⭐⭐⭐ | Partial | Custom | Yes |
| ParseHub | Free personal projects | ⭐⭐⭐ | Yes | $0 (limited) | Yes |
What to Look for in a Browse AI Alternative
Before picking a tool, consider these key factors:
- Reliability when websites change — Does the tool auto-adapt, or will you constantly fix broken scrapers?
- Pricing transparency — Are you paying per robot run, per page, or per API call? Calculate your expected monthly cost before committing.
- Ease of use vs. flexibility — No-code tools are faster to set up but harder to customize. API tools give you full control.
- AI capabilities — Modern AI-powered extractors handle layout changes automatically and require no XPath maintenance.
- Developer integration — If you're building a pipeline, check for SDK support, webhook delivery, and schema-based output.
- Support and SLAs — For production workloads, check what happens when something breaks at 2am.
Why ScrapeGraphAI is the Best Browse AI Alternative
Browse AI's robot-based model made sense in 2020, but AI-native scraping has moved the bar significantly. Here's why ScrapeGraphAI stands out:
No Recording, No Maintenance
ScrapeGraphAI uses LLMs to understand page content dynamically. When a website's layout changes, there's nothing to re-record or fix — the AI adapts automatically.
Natural Language Prompts
Instead of clicking through a visual builder, you describe what you want in plain English. "Extract all job titles, companies, and salaries from this page" is a complete extraction spec.
Structured Output with Schema Validation
Define a Pydantic model and get back validated, type-safe JSON every time. No post-processing, no cleaning.
Better Value
ScrapeGraphAI starts at $20/month — close to Browse AI's $19/month Starter plan — but gives you significantly more power, flexibility, and AI capability for a comparable price.
Developer-First Design
SDKs for Python and JavaScript, LangChain and LangGraph integration, OpenAPI documentation, and full schema support make ScrapeGraphAI a natural fit for any data pipeline.
Frequently Asked Questions
What are the main limitations of Browse AI?
Browse AI relies on visual robot recordings that break when websites change their layout. It has limited AI capabilities, no natural language extraction, and becomes expensive at scale. It also lacks developer-friendly APIs for schema-based, programmatic extraction.
Is there a free Browse AI alternative?
Yes. ScrapeGraphAI has a free tier, Apify gives $5 in monthly credit, Firecrawl offers 500 free pages/month, and ParseHub has a free desktop plan. Each has limits but lets you get started without a credit card.
Which Browse AI alternative is best for non-technical users?
Octoparse and ParseHub are the strongest no-code alternatives. Both offer visual builders with AI-assisted pattern detection, making them accessible without programming knowledge.
Which Browse AI alternative is best for developers?
ScrapeGraphAI is the best for developers who want a clean API, schema-based extraction, and LLM/AI framework integration. ScrapingBee is a good complement for anti-bot proxy infrastructure.
Can I use Browse AI alternatives for monitoring websites?
Yes. Apify, Octoparse, and ScrapeGraphAI all support scheduled runs that can monitor pages for changes. ScrapeGraphAI's AI approach is particularly useful here since it adapts when monitored pages change their structure.
How does ScrapeGraphAI compare to Browse AI in pricing?
ScrapeGraphAI starts at $20/month and Browse AI at $19/month — nearly identical entry pricing. But ScrapeGraphAI's credits go further — you get AI-powered extraction on any website without needing to pre-build and maintain robots. Browse AI's costs scale with robot runs and credits, which can become expensive for monitoring many pages.
Which is best for scraping at enterprise scale?
Zyte is purpose-built for enterprise scraping with SLA-backed infrastructure and a 100M+ proxy network. ScrapeGraphAI also offers enterprise plans with dedicated support. Apify is a middle ground for teams that need scale with a managed cloud platform.
Conclusions
Browse AI is a useful tool for simple, one-off monitoring tasks — but it wasn't designed for the era of AI-native data extraction. Its robot model breaks silently, scales expensively, and lacks the developer integrations that modern data pipelines require.
The good news is there are excellent alternatives for every use case:
- ScrapeGraphAI — Best overall for AI-powered, schema-based extraction
- Apify — Best for pre-built marketplace scrapers
- Octoparse — Best for no-code power users
- ScrapingBee — Best for developer-managed proxy and anti-bot infrastructure
- Firecrawl — Best for LLM and AI application pipelines
- Zyte — Best for enterprise-grade scale and SLAs
- ParseHub — Best free option for individuals and small projects
For most teams building data pipelines or scaling beyond simple monitoring, ScrapeGraphAI offers the best combination of AI capability, pricing, and developer experience. Start with the free tier and see how much easier scraping can be when the AI does the heavy lifting.
Related Resources
- AI Agent Web Scraping - How AI is transforming web data collection
- Apify Alternatives - Compare Apify to other platforms
- Web Scraping Legality - Know the rules before you scrape