TL;DR
Generate high-quality B2B leads from LinkedIn using AI-powered ScrapeGraphAI. Extract profiles, job titles, and company data for sales prospecting at scale.
1. Introduction
LinkedIn is a goldmine for B2B leads; it has millions of real people with updated data like their current job,title, and education. All of this can be used to generate high-quality leads and help you achieve your targets. ScrapeGraphAI will help you achieve your lead generation targets by helping you scrape this data from LinkedIn easily with robust mechanisms. The LinkedIn extraction guide covers the profile-to-JSON workflow in detail. By the end of this article, you will learn how to use ScrapeGraphAI to help you generate high-quality organic leads from LinkedIn. Please read until the end to get the most out of this.
2. ScrapeGraphAI Overview
ScrapeGraphAI is an AI powered smart scraping solution. It is different form traditional scrapers because unlike traditional scrapers who scrape everything and take a lot of manual work to pinpoint and get specific data from a web page,whereas ScrapeGraphAI can pinpoint extract exactly what you want from a given webpage with high accuracy and lighting fast speeds.
ScrapeGraphAI can extract data from Linkedin with any given profile without getting blocked. This power of ScrapeGraphAI allows us to use it for high quality lead generation.
3. Setup & Configuration
You need to go to https://scrapegraphai.com/signup and get an API key
4. The Lead Extraction Process
This process involves using Python code with the scrapegraph_py library to extract LinkedIn profile data. Here are the detailed steps and the code snippets involved:
Step 1: Set Up the Environment
First, make sure you have the necessary Python libraries installed. You'll need scrapegraph_py, pydantic, and pandas. You can install them using pip:
pip install scrapegraph\_py pydantic pandasStep 2: Import Libraries and Initialize the Client
Now, let's start with the Python code. First, we need to import the required libraries and initialize the Client from scrapegraph_py:
import json
import csv
import pandas as pd
from pydantic import BaseModel, Field
from scrapegraph_py import ScrapeGraphAI
from typing import List, Optional
import time
from datetime import datetime
# Initialize the client
sgai = ScrapeGraphAI(api_key="sgai-xxxxxxxxxxxxxxxxxxxxxxx")Step 3: Define the Data Model
We'll use Pydantic to define the structure of the data we want to extract from LinkedIn profiles:
class LeadData(BaseModel):
name: str \= Field(description="Lead name")
company: str \= Field(description="Lead company")
job\_title: str \= Field(description="Lead job title")
location: str \= Field(description="Lead location")Step 4: Create a Function to Scrape a Single LinkedIn Profile
Next, we'll create a function to scrape data from a single LinkedIn profile URL:
def scrape_linkedin_profile(url: str) -> Optional[dict]:
"""Scrape a single LinkedIn profile and return the data as a dictionary"""
try:
response = sgai.extract(
"Extract the data about this person including their name, current company, job title, and location",
url=url,
schema=LeadData.model_json_schema(),
)
if response.status != "success":
raise RuntimeError("extract failed")
result = response.data.json_data
result['linkedin_url'] = url
return result
except Exception as e:
print(f"Error scraping {url}: {str(e)}")
return {
'name': 'Error',
'company': 'Error',
'job_title': 'Error',
'location': 'Error',
'linkedin_url': url,
}Step 5: Create a Function to Scrape Multiple Profiles
Now, let's create a function to scrape multiple LinkedIn profiles:
def scrape\_multiple\_profiles(linkedin\_urls: List\[str\], delay: float \= 2.0) \-\>
List\[dict\]:
"""Scrape multiple LinkedIn profiles and return results as a list of dictionaries
Args:
linkedin\_urls: List of LinkedIn profile URLs
delay: Delay between requests in seconds to avoid rate limiting
Returns:
List of dictionaries containing scraped data
"""
results \= \[\]
print(f"Starting to scrape {len(linkedin\_urls)} LinkedIn profiles...")
for i, url in enumerate(linkedin\_urls, 1):
print(f"Scraping profile {i}/{len(linkedin\_urls)}: {url}")
result \= scrape\_linkedin\_profile(url)
if result:
results.append(result)
\# Add delay between requests to avoid rate limiting
if i \< len(linkedin\_urls):
print(f"Waiting {delay} seconds before next request...")
time.sleep(delay)
return results
Step 6: Create a Function to Save Data to CSV
We'll create a function to save the extracted data to a CSV file:
def save\_to\_csv(results: List\[dict\], filename: str \= None) \-\> str:
"""Save scraped results to a CSV file
Args:
results: List of dictionaries containing scraped data
filename: Optional filename, if not provided, uses timestamp
Returns:
The filename of the saved CSV file
"""
if not filename:
timestamp \= datetime.now().strftime("%Y%m%d\_%H%M%S")
filename \= f"linkedin\_leads\_{timestamp}.csv"
\# Ensure filename has .csv extension
if not filename.endswith('.csv'):
filename \+= '.csv'
if not results:
print("No results to save\!")
return filename
\# Define the column order
fieldnames \= \['name', 'company', 'job\_title', 'location', 'linkedin\_url'\]
try:
with open(filename, 'w', newline='', encoding='utf-8') as csvfile:
writer \= csv.DictWriter(csvfile, fieldnames=fieldnames)
\# Write header
writer.writeheader()
\# Write data rows
for result in results:
writer.writerow(result)
print(f"✅ Successfully saved {len(results)} profiles to {filename}")
return filename
except Exception as e:
print(f"❌ Error saving to CSV: {str(e)}")
return filename
def save\_to\_csv\_pandas(results: List\[dict\], filename: str \= None) \-\> str:
"""Alternative method to save using pandas (requires pandas installation)
Args:
results: List of dictionaries containing scraped data
filename: Optional filename, if not provided, uses timestamp
Returns:
The filename of the saved CSV file
"""
if not filename:
timestamp \= datetime.now().strftime("%Y%m%d\_%H%M%S")
filename \= f"linkedin\_leads\_{timestamp}.csv"
\# Ensure filename has .csv extension
if not filename.endswith('.csv'):
filename \+= '.csv'
if not results:
print("No results to save\!")
return filename
try:
\# Create DataFrame
df \= pd.DataFrame(results)
\# Reorder columns for better readability
column\_order \= \['name', 'company', 'job\_title', 'location',
'linkedin\_url'\]
df \= df.reindex(columns=column\_order)
\# Save to CSV
df.to\_csv(filename, index=False, encoding='utf-8')
print(f"✅ Successfully saved {len(results)} profiles to {filename}")
print(f"📊 Preview of saved data:")
print(df.head())
return filename
except Exception as e:
print(f"❌ Error saving to CSV with pandas: {str(e)}")
return filename
Step 7: Main Execution Block
Finally, let's add the main execution block to run the scraping process:
\# Main execution
if \_\_name\_\_ \== "\_\_main\_\_":
linkedin\_urls \= \[
"https://www.linkedin.com/in/kunal-kushwaha/",
"https://www.linkedin.com/in/satyanadella/",
"https://www.linkedin.com/in/jeffweiner08/",
"https://www.linkedin.com/in/reidhoffman/",
\# Add more URLs as needed
\]
\# Scrape all profiles
print("🚀 Starting LinkedIn scraping process...")
results \= scrape\_multiple\_profiles(linkedin\_urls, delay=2.0)
if results:
print(f"\\n📋 Successfully scraped {len(results)} profiles")
\# Save to CSV using standard library (recommended)
csv\_filename \= save\_to\_csv(results, "linkedin\_leads.csv")
\# Alternative: Save using pandas (uncomment if you prefer pandas)
\# csv\_filename \= save\_to\_csv\_pandas(results,
"linkedin\_leads\_pandas.csv")
print(f"\\n💾 Data saved to: {csv\_filename}")
\# Display summary
print("\\n📊 Scraping Summary:")
for i, result in enumerate(results, 1):
print(f"{i}. {result.get('name', 'N/A')} \- {result.get('company', 'N/A')}
({result.get('job\_title', 'N/A')})")
else:
print("❌ No profiles were successfully scraped\!")
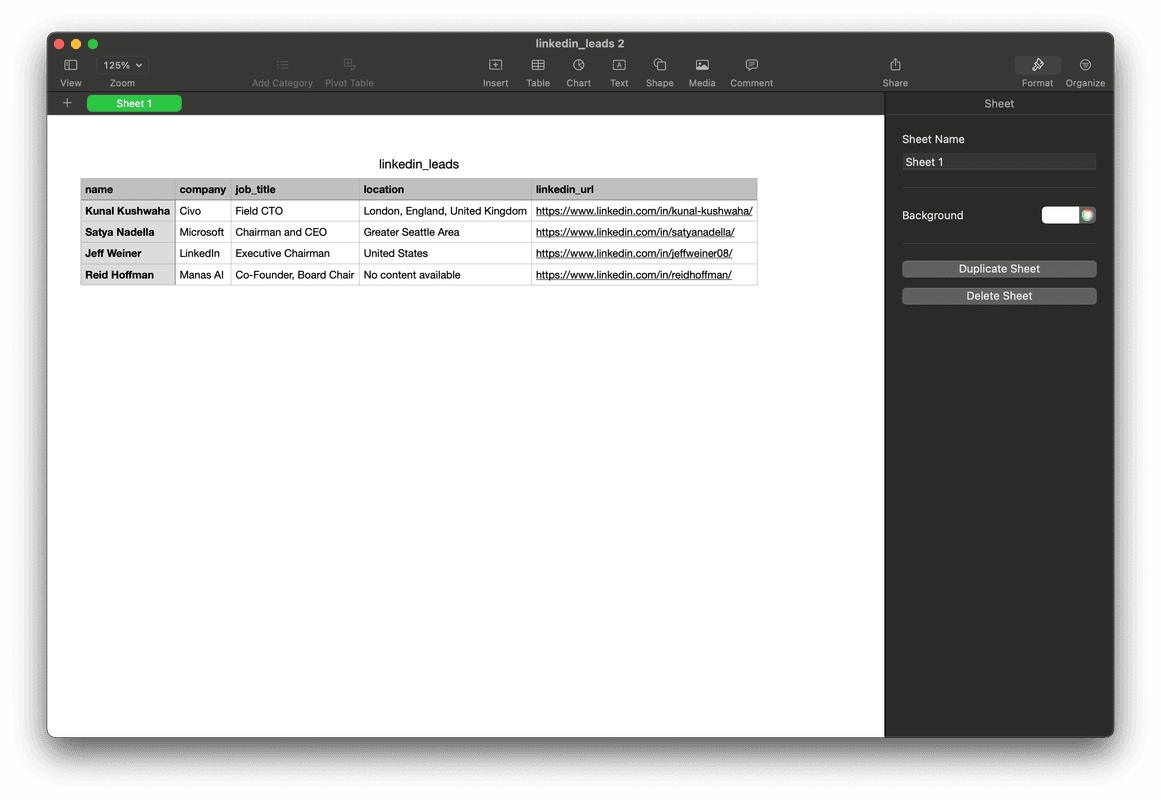
5.Results
6. Conclusion
This is how you can use ScrapeGraphAI to get data about the leads from LinkedIn. You can incorporate this into your data collection work or harness its power in an AI agent which will do research for you.
7. FAQ
What is ScrapeGraphAI?
ScrapeGraphAI is an AI-powered smart scraping solution that extracts specific data from web pages with high accuracy and speed, unlike traditional scrapers that extract everything.
How is ScrapeGraphAI different from traditional web scrapers?
Traditional scrapers often require a lot of manual work to pinpoint and extract specific data, while ScrapeGraphAI uses AI to precisely extract the desired data, making the process faster and more accurate.
How do I get an API key for ScrapeGraphAI?
Go to https://scrapegraphai.com/signup to obtain an API key.
What data can I extract from LinkedIn profiles using ScrapeGraphAI?
You can extract data such as the lead's name, current company, job title, and location.
How do I avoid rate limiting while scraping LinkedIn profiles?
To avoid rate limiting, introduce a delay between requests. The provided Python code includes a delay parameter in the scrape_multiple_profiles function to manage this.
How is the extracted data saved?
The extracted data is saved to a CSV file. The script provides functions to save the data using both the standard Python CSV library and the pandas library.
Can I scrape multiple LinkedIn profiles at once?
Yes, the provided Python script includes a function scrape_multiple_profiles that allows scraping data from multiple LinkedIn profile URLs.
What happens if an error occurs during scraping?
If an error occurs during scraping a specific profile, the script will print an error message and save placeholder data ('Error') for that profile's details in the CSV output to ensure all URLs are tracked.
How can I customize the data extracted from LinkedIn profiles?
You can customize the data extracted by modifying the LeadData Pydantic model. Add or remove fields in the model to match the specific data you want to collect.
How can I add more LinkedIn URLs to scrape?
In the main execution block of the Python script, add more URLs to the linkedin_urls list.
Related Resources
Want to learn more about social media data extraction and lead generation? Explore these guides:
- AI Agent Web Scraping - Learn about AI-powered lead generation
- Mastering ScrapeGraphAI - Deep dive into scraping capabilities
- Best Crunchbase Scraper - Pull company and funding data to enrich leads
- Web Scraping Legality - Understand legal considerations These resources will help you understand how to effectively extract and process social media data for lead generation.