TL;DR
ScrapeGraphAI vs BrowserUse: compare AI-powered graph-based scraping with browser automation. Speed benchmarks, features, and which tool fits your workflow.
Introduction
Scraping is a crucial task for business intelligence teams or AI agents to access data from the web for improving products or achieving business goals. This is where ScrapeGraphAI stands tall leading the scraping space. Here is a comparison between ScrapeGraphAI and Browser-Use and how ScrapeGraphAI will help you in your scraping tasks with easily with graph based scraping approach and how you can use ScrapeGraphAI with your agents and give them scraping prowess.
Types of Scrapers
Graph-based scrapers and browser automation are among various web scraping techniques. Graph-based scraping involves mapping a website as a graph to navigate and extract targeted content efficiently. In contrast, browser automation emulates user interactions like clicks and scrolls to scrape data, but it is often slower and more prone to errors.
ScrapeGraphAI and Graph Based Scraping 🕷️
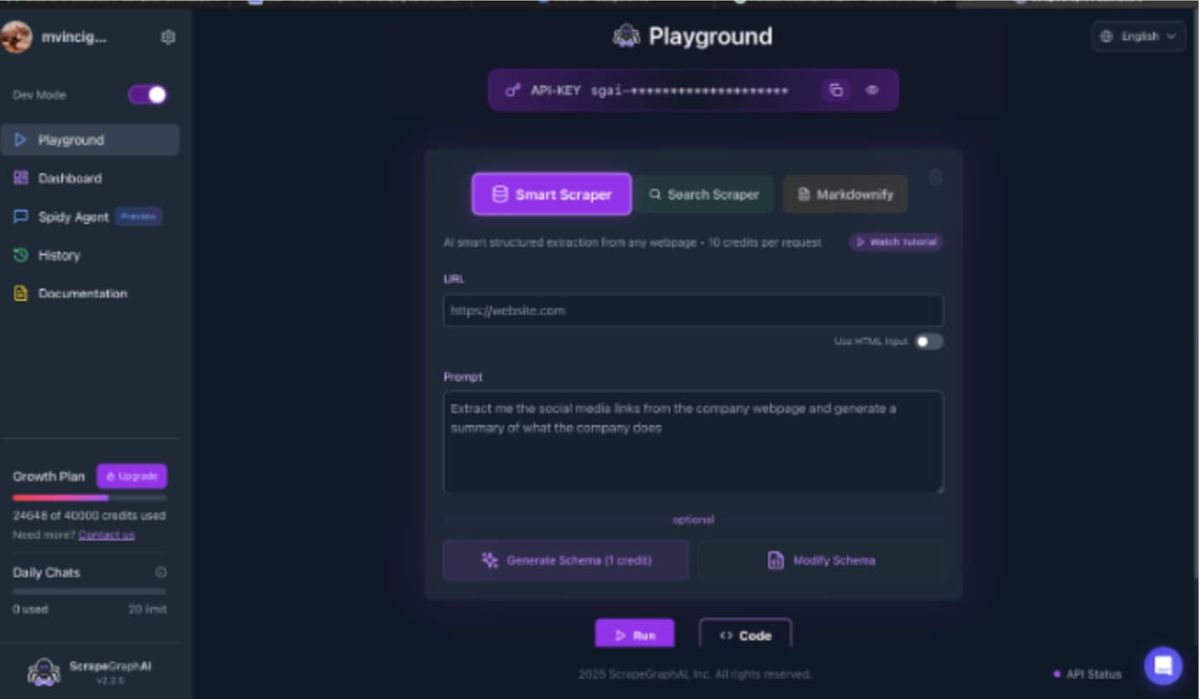
ScrapeGraphAI is an API for extracting data from the web with the use of AI. We work on the graph based philosophy which makes us really fast and smooth in helping you scrape .
We help you with the data scraping part which is focussed on scraping and aggregating information from various sources to gain insights from. This service will fit in your data pipeline perfectly because of the easy to use apis that we provide which are fast and accurate. And it's all AI powered.
What is Browser Use
Browser use is a browser automation tool that does web scraping by emulating the way you would search for websites and get data on websites. It's mainly emulating things like clicking on buttons and opening sites. It is really slow and not production ready.
Comparison
| Feature | ScrapeGraphAI | BrowserUse |
|---|---|---|
| Production Ready | ✅ 24/7 | ❌ Limited stability |
| Speed | ✅ Lightning-fast scraping | ❌ Slower, browser overhead |
| Fault Tolerance | ✅ Auto-recovery built-in | ❌ Crashes on edge cases |
| Ease of Use | ✅ Integrate in blink | ❌ Steeper learning curve |
| Free Credits | ✅ Generous free tier | ❌ Paid from the start |
| Support | ✅ We care about our users | ❌ Minimal or no support |
| API affinity | ✅ Average response time: 3-5s | ❌ Not suited for APIs |
| SDK | ✅ Dedicated SDK's for your favorite languages and lot of integrations | ❌ No SDK's |
| Working method | ✅ Text tokens | ❌ Visual tokens |
Code Examples
1.ScrapeGraphAI
from scrapegraph_py import ScrapeGraphAI
sgai = ScrapeGraphAI() # uses SGAI_API_KEY env var
result = sgai.extract(
url="https://openai.com",
prompt="Extract info about the company",
)We offer simple code structure with dedicated SDK's for python and javascript so that you can focus on building your product and we will handle the scraping for you. It's really simple to use and effective. If you want to use the apis directly you can also do that by using our api endpoints directly.
2.BrowserUse
import json
import time
import requests
API_KEY = 'YOUR_SCRAPEGRAPHAI_API_KEY_HERE'
BASE_URL = 'https://api.browser-use.com/api/v1'
HEADERS = {'Authorization': f'Bearer {API_KEY}'}
def create_task(instructions: str):
"""Create a new browser automation task"""
response = requests.post(f'{BASE_URL}/run-task', headers=HEADERS, json={'task':
instructions})
return response.json()['id']
def get_task_status(task_id: str):
"""Get current task status"""
response = requests.get(f'{BASE_URL}/task/{task_id}/status', headers=HEADERS)
return response.json()
def get_task_details(task_id: str):
"""Get full task details including output"""
response = requests.get(f'{BASE_URL}/task/{task_id}', headers=HEADERS)
return response.json()
def wait_for_completion(task_id: str, poll_interval: int = 2):
"""Poll task status until completion"""
count = 0
unique_steps = []
while True:
details = get_task_details(task_id)
new_steps = details['steps']
# use only the new steps that are not in unique_steps.
if new_steps != unique_steps:
for step in new_steps:
if step not in unique_steps:
print(json.dumps(step, indent=4))
unique_steps = new_steps
count += 1
status = details['status']
if status in ['finished', 'failed', 'stopped']:
return details
time.sleep(poll_interval)
def main():
task_id = create_task('Open https://www.google.com and extract the informations from
openai company')
print(f'Task created with ID: {task_id}')
task_details = wait_for_completion(task_id)
print(f"Final output: {task_details['output']}")
if __name__ == '__main__':
main()
If you look at this code it doesn't provide us with any SDK rather relies solely on the api endpoints.
Integration with agents
ScrapeGraphAI is really easy to integrate with your agents. You can just define ScrapeGraphAI as a tool and your agent now has access to a world class scraping service.
Below is a sample tool that can be used in langgraph for ScrapeGraphAI
def scrape_website(website_url, user_prompt) -> dict:
"""
Perform a scraping request on a website using ScrapeGraphAI.
Parameters:
- website_url (str): The URL of the website to scrape
- user_prompt (str): The data extraction prompt
Returns:
- A dictionary containing the scraped data
"""
sgai = ScrapeGraphAI() # uses SGAI_API_KEY env var
result = sgai.extract(
url=website_url,
prompt=user_prompt,
)
return resultConclusions
If you are searching for a scraping solution ScrapGraphAI is best for you. If you compare both ScrapeGraphAI and BrowserUse, BrowserUse has a huge overhead and is rather a bulky solution which is not yet stable in production.
However, there's a strategic approach that can give you the best of both worlds: using ScrapeGraphAI as your primary scraping solution and BrowserUse only when specific browser automation is absolutely necessary. This hybrid approach allows you to leverage ScrapeGraphAI's speed and reliability for most scraping tasks, while falling back to BrowserUse only for cases that require actual browser interaction. This way, you minimize the overhead and instability issues of BrowserUse while still having access to its browser automation capabilities when needed.
But ScrapeGraphAI provides production ready APIs which help you achieve your scraping goals. With minimal config ScrapeGraphAI is the best solution for your scraping needs.
ScrapeGraphAI can be integrated really quickly, we can handle proxies and provide scraping results lightning fast because of our optimized inference. We provide a free tier for you to test our services. Our APIs are cheaper, faster and without any hallucinations. We also save you infrastructure costs while giving better performance.
Since is based on visual tokens, BrowserUse is not a good choice for scraping because it has a lot of overhead and requires a lot of time for making a request.
A Scraping Bliss for non-tech people
ScrapeGraphAI can be used by non tech people as it has minimal config and easy to use, as compared to the BrowserUse which has a lot of overhead and requires a lot of config. We believe in enabling all our users with the best scraping solutions whether they are technical or non technical people, we care about everyone and focus on making scraping a blissful experience.
Frequently Asked Questions
What is ScrapeGraphAI, and how does it differ from Browser-Use?
ScrapeGraphAI is an AI-powered, graph-based web scraping API that maps websites as graphs to efficiently extract targeted data. It offers fast, production-ready APIs with easy integration. Browser-Use, on the other hand, is a browser automation tool that emulates user interactions like clicks and scrolls, but it is slower, less stable, and not optimized for production environments.
Why should I choose ScrapeGraphAI over Browser-Use?
ScrapeGraphAI provides several advantages: lightning-fast scraping, production-ready stability with auto-recovery, simple APIs and SDKs for Python and JavaScript, a generous free tier, dedicated support, and seamless integration with agents. Browser-Use is slower, has a steeper learning curve, and lacks SDKs or a free tier.
Is ScrapeGraphAI suitable for non-technical users?
Yes, ScrapeGraphAI is designed with minimal configuration, making it accessible for non-technical users. Its easy-to-use APIs and SDKs simplify the scraping process, unlike Browser-Use, which requires more technical setup and configuration.
How reliable is ScrapeGraphAI in production environments?
ScrapeGraphAI is production-ready, operating 24/7 with built-in fault tolerance and auto-recovery mechanisms. It is designed to handle edge cases and maintain stability, unlike Browser-Use, which is prone to crashes and not optimized for production.
How can I access and manage my ScrapeGraphAI account?
You can easily access and manage your ScrapeGraphAI account through the ScrapeGraphAI dashboard. Here you can monitor your API usage, manage your API keys, and access all the features of ScrapeGraphAI in one place.
Can ScrapeGraphAI be integrated with AI agents?
Absolutely. ScrapeGraphAI can be easily defined as a tool in frameworks like LangGraph, enabling AI agents to leverage its world-class scraping capabilities. The provided code example demonstrates how to integrate it with minimal effort.
Related Resources
Want to learn more about different scraping approaches and tools? Check out these relevant guides:
- AI Agent Web Scraping - Learn about AI-powered scraping approaches
- Mastering ScrapeGraphAI - Deep dive into graph-based scraping
- Scraping with JavaScript - JavaScript-based scraping methods
- Scrapy Alternatives - Explore other scraping frameworks
- Web Scraping Legality - Understand the legal aspects of different scraping methods
These resources will help you understand the different approaches to web scraping and choose the right method for your needs.