TL;DR
Combine graph-based scraping with open data platforms like OpenAlex, CORE, and OpenCitations to build richer academic datasets.
- Fill metadata gaps — scrape institution pages, PDFs, and conference sites that APIs miss
- Enrich with open data — merge ScrapeGraphAI extractions with OpenAlex and CORE metadata
- Extract from PDFs — pull titles, abstracts, and findings from academic papers automatically
- Build research pipelines — crawl faculty pages, proceedings, and citation networks at scale
#Empowering Academic Research with Graph-Based Scraping & Open Data
Introduction
Open data and reproducible science are essential pillars of modern academic research. They are widely used in the research community. Yet, even the datasets which are labeled "open" often hide in fragmented formats —academic portals, departmental pages, PDFs—making them difficult to harvest and integrate, which is a major issue while doing research and collecting data for academics. Traditional APIs l(OpenAlex, CORE, OpenCitations) cover a broad scope, but aren't comprehensive and lack some data that is important to and very useful too. This blog post demonstrates how to combine graph-based scraping with open data platforms using ScrapeGraphAI to streamline, enrich, and visualize academic pipelines and improve your academic research and data collection.
1. Open‑Source Academic Platforms At a Glance
OpenAlex hosts metadata on 209 M scholarly works, including authors, citations, institutions, and topics—accessible via a modern REST API.
OpenCitations and the Initiative for Open Citations (I4OC) promote open citation data (DOI-to-DOI), with OpenCitations covering upwards of 13 M links.
CORE aggregates over 125 M open-access papers by providing an API and data dumps.

These platforms are powerful and have a lot of data useful for research —but they leave gaps in domain-specific, PDF-heavy, or institution-specific data which can be an impediment to your research endeavours and data collection.
2. Why Graph-Based Scraping Still Matters
While open APIs are invaluable and may provide you with a a lot of important data, researchers often still need following data which is hard to find because there is no central dataset surrounding it: Institution-level data — e.g., scratch faculty updates, conference pages, PDF syllabi.
Visual/PDF ingestion — tables, graphs, or charts embedded mid-PDF.
Contextual enrichment — metadata gaps like abstract, keywords, or cross-citations.
ScrapeGraphAI's graph-based pipelines can crawl websites like a mini spider, intelligently extract embedded assets, and integrate results with open metadata sources. Which will help you get the above crucial data that you missed and aid as well as boost your research and data collection by many folds seamlessly.
What is ScrapeGraphAI?
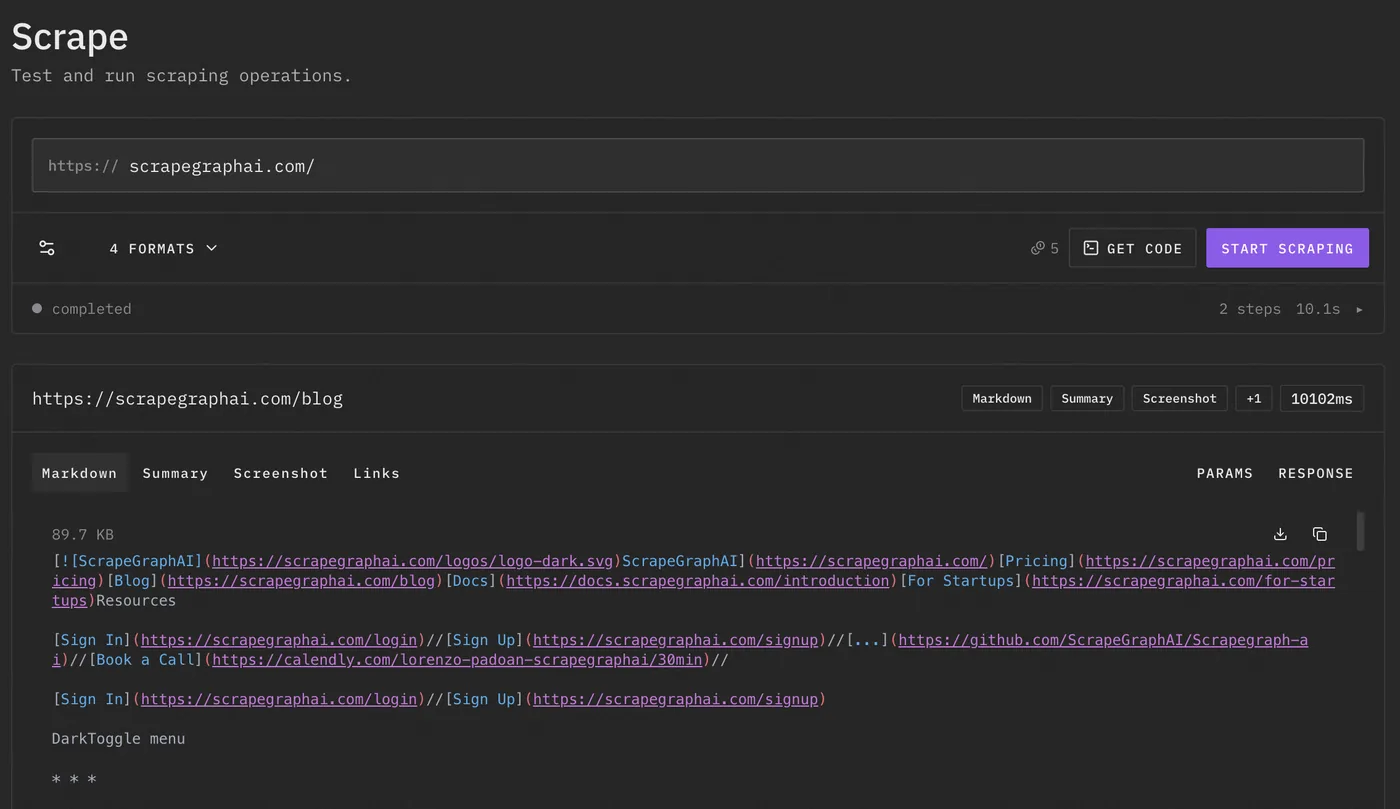
ScrapeGraphAI is an API for extracting data from the web with the use of AI. ScrapeGraphAI uses graph based scraping . This service will fit in your data pipeline perfectly because of the easy to use apis that we provide which are fast and accurate. And it's all AI powered and integrates easily with any no code platform like n8n, bubble or make.We offer fast, production-grade APIs , Python & JS SDKs, auto-recovery,Agent-friendly integration (LangGraph, LangChain, etc.) and free tier + robust support
3. Build a Research Pipeline with ScrapeGraphAI
a. Crawl Institutional Pages
from scrapegraph_py import ScrapeGraphAI
sgai = ScrapeGraphAI(api_key="YOUR_KEY")
response = sgai.extract(
"Extract names, titles, profile URLs of faculty",
url="https://example.edu/faculty",
)
print(response.data.json_data)b. Extract Conference Information
# Scrape conference proceedings and paper listings
conference_response = sgai.extract(
url="https://conference-site.com/proceedings",
prompt="Extract paper titles, authors, abstracts, and DOIs"
)c. PDF Content Extraction
# Extract structured data from PDF documents
pdf_response = sgai.extract(
url="https://arxiv.org/pdf/2301.00001.pdf",
prompt="Extract title, authors, abstract, and key findings"
)4. Integrating with Open Data Sources
Combining ScrapeGraphAI with OpenAlex
import requests
from scrapegraph_py import ScrapeGraphAI
def enrich_paper_data(doi):
# Get basic metadata from OpenAlex
openalex_url = f"https://api.openalex.org/works/doi:{doi}"
metadata = requests.get(openalex_url).json()
# Use ScrapeGraphAI to get additional details
sgai = ScrapeGraphAI(api_key="YOUR_KEY")
if metadata.get('pdf_url'):
enhanced_data = sgai.extract(
url=metadata['pdf_url'],
prompt="Extract methodology, results, and conclusions"
)
return {
'openalex_data': metadata,
'enhanced_content': enhanced_data
}
return metadata5. Research Use Cases
Literature Review Automation
def automated_literature_review(topic, max_papers=50):
"""Automatically collect and analyze papers on a topic"""
# Search OpenAlex for relevant papers
search_url = f"https://api.openalex.org/works?search={topic}&per-page={max_papers}"
papers = requests.get(search_url).json()['results']
enriched_papers = []
for paper in papers:
if paper.get('open_access', {}).get('oa_url'):
# Use ScrapeGraphAI to extract key insights
analysis = sgai.extract(
url=paper['open_access']['oa_url'],
prompt=f"Analyze this paper's contribution to {topic} research"
)
enriched_papers.append({
'title': paper['title'],
'authors': paper['authorships'],
'citations': paper['cited_by_count'],
'analysis': analysis
})
return enriched_papersCitation Network Analysis
def build_citation_network(seed_doi):
"""Build a citation network from a seed paper"""
# Get citations from OpenCitations
citations_url = f"https://opencitations.net/index/coci/api/v1/citations/{seed_doi}"
citations = requests.get(citations_url).json()
network_data = []
for citation in citations:
# Enhance with scraped content
if citation.get('cited_url'):
content = sgai.extract(
url=citation['cited_url'],
prompt="Extract main research question and key findings"
)
network_data.append({
'citing_paper': citation['citing'],
'cited_paper': citation['cited'],
'content_summary': content
})
return network_data6. Advanced Research Workflows
Multi-Source Data Fusion
class ResearchDataFusion:
def __init__(self, api_key):
self.sgai = ScrapeGraphAI(api_key=api_key)
def fuse_sources(self, research_topic):
"""Combine multiple academic data sources"""
# OpenAlex for metadata
openalex_data = self.get_openalex_papers(research_topic)
# CORE for full-text access
core_data = self.get_core_papers(research_topic)
# ScrapeGraphAI for institutional pages
institutional_data = self.scrape_institutions(research_topic)
# Combine and deduplicate
return self.merge_datasets([openalex_data, core_data, institutional_data])
def scrape_institutions(self, topic):
"""Scrape relevant university departments"""
universities = [
"https://cs.stanford.edu/research",
"https://www.csail.mit.edu/research",
"https://www.cs.cmu.edu/research"
]
institutional_research = []
for uni_url in universities:
data = self.sgai.extract(
url=uni_url,
prompt=f"Find research projects related to {topic}"
)
institutional_research.append(data)
return institutional_researchAutomated Fact-Checking
def verify_research_claims(paper_url, claims_to_verify):
"""Verify specific claims against scraped evidence"""
verification_results = []
for claim in claims_to_verify:
# Search for supporting evidence
evidence = sgai.extract(
url=paper_url,
prompt=f"Find evidence that supports or refutes: {claim}"
)
verification_results.append({
'claim': claim,
'evidence': evidence,
'confidence': assess_evidence_strength(evidence)
})
return verification_results7. Visualization and Analysis
Research Trend Analysis
import matplotlib.pyplot as plt
import pandas as pd
def analyze_research_trends(scraped_data):
"""Analyze trends from scraped research data"""
# Convert to DataFrame for analysis
df = pd.DataFrame(scraped_data)
# Extract publication years and topics
trends = df.groupby(['year', 'topic']).size().reset_index()
# Create visualization
plt.figure(figsize=(12, 8))
for topic in trends['topic'].unique():
topic_data = trends[trends['topic'] == topic]
plt.plot(topic_data['year'], topic_data[0], label=topic)
plt.xlabel('Year')
plt.ylabel('Number of Papers')
plt.title('Research Trends Over Time')
plt.legend()
plt.show()
return trendsCollaboration Network Mapping
import networkx as nx
def map_collaboration_networks(scraped_authors):
"""Create collaboration networks from scraped author data"""
G = nx.Graph()
for paper in scraped_authors:
authors = paper['authors']
# Add nodes for each author
for author in authors:
G.add_node(author['name'],
affiliation=author.get('affiliation'),
papers=author.get('paper_count', 0))
# Add edges for collaborations
for i in range(len(authors)):
for j in range(i+1, len(authors)):
if G.has_edge(authors[i]['name'], authors[j]['name']):
G[authors[i]['name']][authors[j]['name']]['weight'] += 1
else:
G.add_edge(authors[i]['name'], authors[j]['name'], weight=1)
return G8. Best Practices for Academic Scraping
Ethical Guidelines
class EthicalResearchScraper:
def __init__(self, api_key):
self.sgai = ScrapeGraphAI(api_key=api_key)
self.request_delays = {}
def respectful_scrape(self, url, delay=2):
"""Implement respectful scraping practices"""
import time
from urllib.parse import urlparse
domain = urlparse(url).netloc
# Implement per-domain delays
if domain in self.request_delays:
time.sleep(delay)
self.request_delays[domain] = time.time()
# Check robots.txt compliance
if self.check_robots_txt(url):
return self.sgai.extract(
url=url,
prompt="Extract academic content respectfully"
)
else:
print(f"Robots.txt disallows scraping {url}")
return None
def check_robots_txt(self, url):
"""Check robots.txt compliance"""
# Implementation for robots.txt checking
return True # Simplified for exampleData Quality Assurance
def validate_academic_data(scraped_data):
"""Validate scraped academic data quality"""
quality_metrics = {
'completeness': 0,
'accuracy': 0,
'consistency': 0
}
# Check for required fields
required_fields = ['title', 'authors', 'abstract']
complete_records = sum(1 for record in scraped_data
if all(field in record for field in required_fields))
quality_metrics['completeness'] = complete_records / len(scraped_data)
# Additional validation checks...
return quality_metrics9. Future Directions
AI-Enhanced Research Discovery
def ai_research_discovery(research_interests):
"""Use AI to discover relevant research automatically"""
discovery_prompt = f"""
Based on these research interests: {research_interests}
Suggest:
1. Emerging research areas to explore
2. Key papers to read
3. Potential collaboration opportunities
4. Funding opportunities
"""
suggestions = sgai.extract(
url="https://academic-discovery-engine.com",
prompt=discovery_prompt
)
return suggestionsConclusion
Combining graph-based scraping with open academic data sources creates powerful opportunities for research enhancement. ScrapeGraphAI bridges the gaps left by traditional APIs, enabling researchers to:
- Access comprehensive data from multiple sources
- Automate literature reviews and trend analysis
- Enhance collaboration through network mapping
- Verify research claims with cross-referenced evidence
- Discover new research opportunities through AI-powered analysis
The future of academic research lies in intelligent, automated data collection that respects ethical boundaries while maximizing research potential.
Related Resources
Explore more about academic research and data collection:
- AI Agent Web Scraping - Advanced AI techniques
- Mastering ScrapeGraphAI - Complete platform guide
- Building Intelligent Agents - AI agent development
- Web Scraping Legality - Legal considerations
These resources will help you build sophisticated academic research pipelines while maintaining ethical and legal standards.