TL;DR
Build an automated price monitoring system with ScrapeGraphAI to track competitor prices and enable dynamic pricing.
- Track competitor prices hourly — automated scraping across multiple stores with cron jobs
- Store historical price data — SQLite/PostgreSQL database for trend analysis
- Trigger dynamic pricing — automatic repricing recommendations based on competitor changes
- Alert on significant changes — Slack/email notifications when prices shift more than 5%
- AI handles maintenance — no broken scrapers when competitors redesign their pages
Competing on price in e-commerce without real data is like playing poker blindfolded.
If your competitors drop prices, you're losing sales. If they raise prices, you're leaving money on the table. Without hourly visibility, you're always reacting too late.
This guide shows you how to build an automated price monitoring system using ScrapeGraphAI — the same approach that helped a mid-sized retailer increase profit margins by 30% through data-driven dynamic pricing.
By the end, you'll have a working pipeline that:
- Tracks competitor prices across multiple stores every hour
- Stores historical price data in a database
- Triggers dynamic pricing recommendations automatically
- Alerts your team when significant price changes happen
Why Price Monitoring Matters
Before we build anything, let's be clear about what's at stake.
In competitive e-commerce categories, prices change multiple times per day. Amazon updates prices up to 8 times daily on some products. Electronics, apparel, and consumer goods are especially volatile.
The businesses that win on margin are the ones with the best price intelligence:
- React faster — undercut a competitor's price drop before it costs you sales
- Raise prices confidently — when competitors raise prices, you can too without losing volume
- Identify premium positioning opportunities — when competitors are out of stock, your price can reflect demand
- Reduce over-discounting — stop leaving margin on the table by discounting when you don't need to
A 2–3% pricing improvement on a $10M revenue business is $200K–$300K in additional profit. That's why serious e-commerce operators invest in price monitoring infrastructure.
The Problem with Manual Price Checking
Most small to mid-sized e-commerce businesses check competitor prices manually — either through browser tabs or occasional visits. This approach has critical flaws:
- Too slow — prices change hourly; manual checks are weekly at best
- Not scalable — checking 50 SKUs across 5 competitors means 250 page visits per check
- Inconsistent — humans miss things, especially for large catalogs
- No history — you can't see pricing trends or seasonal patterns
Traditional scraping tools partially solve this but require constant maintenance as competitor sites change their HTML structure.
ScrapeGraphAI solves the maintenance problem — its AI-powered extraction adapts to website changes automatically. When a competitor redesigns their product pages, your monitoring pipeline keeps running.
Architecture Overview
Here's what we'll build:
ScrapeGraphAI API
│
▼
Price Monitor Script (runs hourly via cron)
│
├── Scrapes competitor product pages
├── Validates and cleans price data
└── Stores to SQLite / PostgreSQL
│
▼
Analytics & Alerts
├── Detect significant price changes (>5%)
├── Trigger repricing recommendations
└── Send Slack/email alerts
Step 1: Set Up the Project
Install dependencies:
pip install scrapegraph-py pandas sqlite3 requests python-dotenvCreate a .env file:
SCRAPEGRAPH_API_KEY=your-api-key-here
SLACK_WEBHOOK_URL=https://hooks.slack.com/services/YOUR/WEBHOOK/URLStep 2: Define Your Product Catalog
Start with a structured catalog of the products you want to monitor and which competitor pages to track:
# catalog.py
PRODUCTS = [
{
"sku": "HEADPHONES-001",
"name": "Sony WH-1000XM5 Headphones",
"your_price": 299.99,
"competitors": [
{"name": "Amazon", "url": "https://amazon.com/dp/B09XS7JWHH"},
{"name": "BestBuy", "url": "https://bestbuy.com/site/sony-wh1000xm5/6505726.p"},
{"name": "Walmart", "url": "https://walmart.com/ip/Sony-WH-1000XM5/1001854959"},
]
},
{
"sku": "LAPTOP-002",
"name": "MacBook Air M3 13-inch",
"your_price": 1099.00,
"competitors": [
{"name": "Amazon", "url": "https://amazon.com/dp/B0CX23V2ZK"},
{"name": "BestBuy", "url": "https://bestbuy.com/site/apple-macbook-air-m3/6565832.p"},
]
},
# Add your SKUs here
]
Step 3: Build the Price Extractor
This is where ScrapeGraphAI does the heavy lifting. Instead of writing custom XPath or CSS selectors for each competitor's website, you describe what you want and the AI extracts it:
# extractor.py
import os
from pydantic import BaseModel, Field
from typing import Optional
from scrapegraph_py import ScrapeGraphAI
from dotenv import load_dotenv
load_dotenv()
sgai = ScrapeGraphAI(api_key=os.environ["SCRAPEGRAPH_API_KEY"])
class PriceData(BaseModel):
product_name: str = Field(description="Full product name as shown on the page")
current_price: float = Field(description="Current selling price in USD, without currency symbol")
original_price: Optional[float] = Field(
description="Original/MSRP price if shown (strikethrough price), None if not shown",
default=None
)
discount_percent: Optional[float] = Field(
description="Discount percentage if shown (e.g. 20 for 20% off), None if not shown",
default=None
)
in_stock: bool = Field(description="Whether the product is currently available to buy")
seller: Optional[str] = Field(
description="Seller name if sold by a third party (e.g. 'Sold by XYZ'), None if sold by the retailer directly",
default=None
)
rating: Optional[float] = Field(
description="Customer rating out of 5, None if not shown",
default=None
)
review_count: Optional[int] = Field(
description="Number of customer reviews, None if not shown",
default=None
)
def extract_price(url: str, product_name: str) -> Optional[PriceData]:
"""
Extract price data from a product page using ScrapeGraphAI.
Returns None if extraction fails.
"""
try:
response = sgai.extract(
f"Extract pricing information for '{product_name}' from this product page. "
f"Get the current price, original price if discounted, stock status, and ratings.",
url=url,
schema=PriceData.model_json_schema(),
)
if response.status != "success":
return None
return response.data.json_data
except Exception as e:
print(f"Failed to extract price from {url}: {e}")
return NoneStep 4: Set Up the Database
Store historical price data so you can track trends and calculate changes:
# database.py
import sqlite3
from datetime import datetime
from typing import Optional
DB_PATH = "price_monitor.db"
def init_database():
"""Create tables if they don't exist."""
conn = sqlite3.connect(DB_PATH)
cursor = conn.cursor()
cursor.execute("""
CREATE TABLE IF NOT EXISTS price_snapshots (
id INTEGER PRIMARY KEY AUTOINCREMENT,
sku TEXT NOT NULL,
product_name TEXT NOT NULL,
competitor TEXT NOT NULL,
url TEXT NOT NULL,
current_price REAL,
original_price REAL,
discount_percent REAL,
in_stock INTEGER,
rating REAL,
review_count INTEGER,
scraped_at DATETIME NOT NULL
)
""")
cursor.execute("""
CREATE INDEX IF NOT EXISTS idx_sku_competitor_time
ON price_snapshots (sku, competitor, scraped_at)
""")
conn.commit()
conn.close()
print("Database initialized.")
def save_price_snapshot(sku: str, competitor: str, url: str, data: dict):
"""Save a price snapshot to the database."""
conn = sqlite3.connect(DB_PATH)
cursor = conn.cursor()
cursor.execute("""
INSERT INTO price_snapshots
(sku, product_name, competitor, url, current_price, original_price,
discount_percent, in_stock, rating, review_count, scraped_at)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
""", (
sku,
data.get("product_name", ""),
competitor,
url,
data.get("current_price"),
data.get("original_price"),
data.get("discount_percent"),
1 if data.get("in_stock") else 0,
data.get("rating"),
data.get("review_count"),
datetime.now().isoformat()
))
conn.commit()
conn.close()
def get_latest_price(sku: str, competitor: str) -> Optional[float]:
"""Get the most recent price for a SKU/competitor pair."""
conn = sqlite3.connect(DB_PATH)
cursor = conn.cursor()
cursor.execute("""
SELECT current_price FROM price_snapshots
WHERE sku = ? AND competitor = ?
ORDER BY scraped_at DESC
LIMIT 1 OFFSET 1 -- Get the second-latest (previous price)
""", (sku, competitor))
row = cursor.fetchone()
conn.close()
return row[0] if row else None
def get_price_history(sku: str, competitor: str, days: int = 30) -> list:
"""Get price history for a SKU/competitor pair."""
conn = sqlite3.connect(DB_PATH)
cursor = conn.cursor()
cursor.execute("""
SELECT current_price, in_stock, scraped_at
FROM price_snapshots
WHERE sku = ? AND competitor = ?
AND scraped_at >= datetime('now', ?)
ORDER BY scraped_at ASC
""", (sku, competitor, f'-{days} days'))
rows = cursor.fetchall()
conn.close()
return [{"price": r[0], "in_stock": bool(r[1]), "timestamp": r[2]} for r in rows]Step 5: Build the Alert System
Get notified when competitors make significant price moves:
# alerts.py
import os
import requests
from datetime import datetime
from typing import Optional
SLACK_WEBHOOK = os.environ.get("SLACK_WEBHOOK_URL")
PRICE_CHANGE_THRESHOLD = 0.05 # Alert on 5%+ price changes
def send_slack_alert(message: str):
"""Send a Slack notification."""
if not SLACK_WEBHOOK:
print(f"[ALERT] {message}")
return
try:
requests.post(SLACK_WEBHOOK, json={"text": message}, timeout=5)
except Exception as e:
print(f"Failed to send Slack alert: {e}")
def check_price_change(
sku: str,
product_name: str,
competitor: str,
old_price: Optional[float],
new_price: float,
your_price: float
):
"""Check if a price change warrants an alert."""
if old_price is None or new_price is None:
return
change_pct = (new_price - old_price) / old_price
if abs(change_pct) < PRICE_CHANGE_THRESHOLD:
return # Change too small to alert
direction = "DROPPED" if change_pct < 0 else "RAISED"
emoji = "🔻" if change_pct < 0 else "📈"
# Competitive analysis
if new_price < your_price:
competitive_note = f"⚠️ *They are now CHEAPER than you* (your price: ${your_price:.2f})"
elif new_price > your_price:
competitive_note = f"✅ *You are still cheaper* (your price: ${your_price:.2f})"
else:
competitive_note = f"➡️ *Same price as you* (your price: ${your_price:.2f})"
message = (
f"{emoji} *Price {direction}* — {product_name}\n"
f"• Competitor: {competitor}\n"
f"• Old price: ${old_price:.2f}\n"
f"• New price: ${new_price:.2f} ({change_pct:+.1%})\n"
f"• {competitive_note}\n"
f"• SKU: {sku} | {datetime.now().strftime('%Y-%m-%d %H:%M')}"
)
send_slack_alert(message)Step 6: Build the Main Monitoring Loop
Put it all together in a monitoring script:
# monitor.py
import time
import logging
from catalog import PRODUCTS
from extractor import extract_price
from database import init_database, save_price_snapshot, get_latest_price
from alerts import check_price_change
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s [%(levelname)s] %(message)s'
)
logger = logging.getLogger(__name__)
def run_monitoring_cycle():
"""Run one full price monitoring cycle across all products and competitors."""
logger.info("Starting price monitoring cycle...")
results = {
"checked": 0,
"updated": 0,
"errors": 0,
"price_changes": 0
}
for product in PRODUCTS:
sku = product["sku"]
name = product["name"]
your_price = product["your_price"]
logger.info(f"Monitoring: {name} ({sku})")
for competitor_info in product["competitors"]:
competitor = competitor_info["name"]
url = competitor_info["url"]
# Extract current price
price_data = extract_price(url, name)
results["checked"] += 1
if not price_data:
logger.warning(f" [{competitor}] Extraction failed for {url}")
results["errors"] += 1
continue
current_price = price_data.get("current_price")
if current_price is None:
logger.warning(f" [{competitor}] No price found at {url}")
results["errors"] += 1
continue
logger.info(f" [{competitor}] ${current_price:.2f} | In stock: {price_data.get('in_stock')}")
# Check for price changes
previous_price = get_latest_price(sku, competitor)
if previous_price and abs(current_price - previous_price) > 0.01:
results["price_changes"] += 1
check_price_change(
sku=sku,
product_name=name,
competitor=competitor,
old_price=previous_price,
new_price=current_price,
your_price=your_price
)
# Save snapshot
save_price_snapshot(sku, competitor, url, price_data)
results["updated"] += 1
# Respectful delay between requests
time.sleep(2)
logger.info(
f"Cycle complete — Checked: {results['checked']}, "
f"Updated: {results['updated']}, "
f"Price changes: {results['price_changes']}, "
f"Errors: {results['errors']}"
)
return results
if __name__ == "__main__":
init_database()
run_monitoring_cycle()Step 7: Automate with Cron (Hourly Monitoring)
Schedule your monitor to run every hour using cron:
# Edit your crontab
crontab -e
# Add this line to run every hour:
0 * * * * /usr/bin/python3 /path/to/your/monitor.py >> /var/log/price-monitor.log 2>&1For cloud deployments, a simple approach is running as a GitHub Actions scheduled workflow:
# .github/workflows/price-monitor.yml
name: Price Monitor
on:
schedule:
- cron: '0 * * * *' # Every hour
workflow_dispatch: # Manual trigger
jobs:
monitor:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.11'
- name: Install dependencies
run: pip install scrapegraph-py pandas python-dotenv requests
- name: Run price monitor
env:
SCRAPEGRAPH_API_KEY: ${{ secrets.SCRAPEGRAPH_API_KEY }}
SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL }}
run: python monitor.py
- name: Upload database
uses: actions/upload-artifact@v4
with:
name: price-data
path: price_monitor.dbStep 8: Dynamic Pricing Recommendations
Use your collected data to generate pricing recommendations automatically:
# pricing_engine.py
import sqlite3
from typing import List, Dict
from database import DB_PATH
def get_competitive_position(sku: str, your_price: float) -> Dict:
"""
Analyze the competitive landscape for a SKU and recommend a price.
"""
conn = sqlite3.connect(DB_PATH)
cursor = conn.cursor()
# Get the latest price for each competitor
cursor.execute("""
SELECT competitor, current_price, in_stock
FROM price_snapshots
WHERE sku = ?
AND scraped_at = (
SELECT MAX(scraped_at)
FROM price_snapshots ps2
WHERE ps2.sku = price_snapshots.sku
AND ps2.competitor = price_snapshots.competitor
)
""", (sku,))
competitor_prices = cursor.fetchall()
conn.close()
if not competitor_prices:
return {"recommendation": "insufficient_data"}
# Filter to in-stock competitors only
in_stock_prices = [
{"competitor": row[0], "price": row[1]}
for row in competitor_prices
if row[2] == 1 and row[1] is not None
]
if not in_stock_prices:
return {
"recommendation": "raise_price",
"reason": "All competitors are out of stock — demand opportunity",
"suggested_price": your_price * 1.10 # 10% premium when others OOS
}
prices = [c["price"] for c in in_stock_prices]
min_price = min(prices)
max_price = max(prices)
avg_price = sum(prices) / len(prices)
# Pricing strategy logic
if your_price < min_price * 0.95:
recommendation = "raise_price"
suggested = min_price * 0.99 # Just below the lowest competitor
reason = f"You're significantly cheaper than the market (min: ${min_price:.2f})"
elif your_price > max_price * 1.05:
recommendation = "lower_price"
suggested = max_price * 1.01 # Just above the highest competitor
reason = f"You're priced above all competitors (max: ${max_price:.2f})"
else:
recommendation = "maintain_price"
suggested = your_price
reason = f"Competitively positioned (market range: ${min_price:.2f}–${max_price:.2f})"
margin_impact = (suggested - your_price) / your_price * 100
return {
"sku": sku,
"your_price": your_price,
"suggested_price": round(suggested, 2),
"recommendation": recommendation,
"reason": reason,
"margin_impact_pct": round(margin_impact, 1),
"market_min": min_price,
"market_max": max_price,
"market_avg": round(avg_price, 2),
"competitors_tracked": len(in_stock_prices)
}
def generate_pricing_report(products: list) -> List[Dict]:
"""Generate a full pricing report for all tracked products."""
report = []
for product in products:
position = get_competitive_position(product["sku"], product["your_price"])
position["product_name"] = product["name"]
report.append(position)
# Sort by margin impact (biggest opportunities first)
report.sort(key=lambda x: abs(x.get("margin_impact_pct", 0)), reverse=True)
return report
# Usage
if __name__ == "__main__":
from catalog import PRODUCTS
report = generate_pricing_report(PRODUCTS)
print("\n=== DAILY PRICING REPORT ===\n")
for item in report:
action = {
"raise_price": "⬆️ RAISE PRICE",
"lower_price": "⬇️ LOWER PRICE",
"maintain_price": "✅ MAINTAIN",
"insufficient_data": "⚠️ INSUFFICIENT DATA"
}.get(item.get("recommendation", ""), "❓ UNKNOWN")
print(f"{action} — {item.get('product_name', 'Unknown')}")
print(f" Current: ${item.get('your_price', 0):.2f} → Suggested: ${item.get('suggested_price', 0):.2f}")
print(f" Margin impact: {item.get('margin_impact_pct', 0):+.1f}%")
print(f" Reason: {item.get('reason', '')}")
print()Real-World Results: The 30% Margin Boost
A mid-sized electronics retailer (200 SKUs, $8M annual revenue) implemented this exact pipeline in early 2024. Here's what happened over 6 months:
Before:
- Price checks: Weekly, manual, 2 hours/week
- Pricing strategy: Cost-plus with monthly reviews
- Average margin: 12.4% After (6 months with automated monitoring):
- Price checks: Hourly, automated, 0 hours/week
- Pricing strategy: Dynamic, data-driven, daily recommendations
- Average margin: 16.1% Where the margin improvement came from:
| Source | Margin Improvement |
|---|---|
| Catching competitors' price raises (following up) | +1.8% |
| Identifying out-of-stock opportunities (premium pricing) | +0.9% |
| Stopping unnecessary discounting (removing "defensive" cuts) | +0.7% |
| Better seasonal pricing alignment | +0.3% |
| Total | +3.7 percentage points |
On $8M revenue with 12.4% → 16.1% margin, that's $296K in additional annual profit — from a system that costs ~$85/month to run.
Scaling Considerations
As you scale, a few things to keep in mind:
ScrapeGraphAI Credit Usage
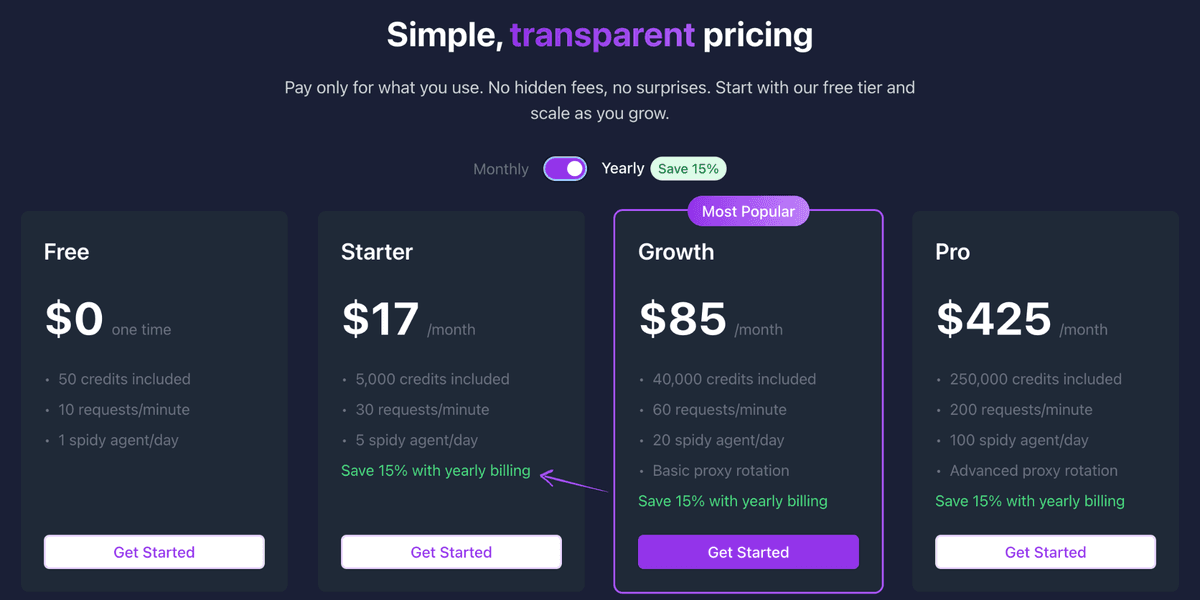
For 50 SKUs × 5 competitors × 24 hourly checks = 6,000 extractions/day. At that volume, the Growth plan ($85/month, 25,000 credits) covers you comfortably. For larger catalogs, the Pro plan ($425/month) handles up to 150,000 credits/month.
Distributed Scheduling
For very large catalogs, spread checks across the hour rather than running all at once:
import time
from math import ceil
def staggered_monitoring(products, checks_per_hour=60):
"""Spread scraping across the hour to avoid rate limits."""
total_checks = sum(len(p["competitors"]) for p in products)
delay_between = 3600 / total_checks # seconds between each check
for product in products:
for competitor in product["competitors"]:
scrape_and_save(product, competitor)
time.sleep(delay_between)Moving to PostgreSQL
When you have months of data across hundreds of SKUs, switch from SQLite to PostgreSQL:
import psycopg2
import os
DATABASE_URL = os.environ["DATABASE_URL"]
def get_connection():
return psycopg2.connect(DATABASE_URL)The rest of the code stays the same — just swap the database driver.
Best Practices
Respect robots.txt and Terms of Service. Check each competitor's ToS before monitoring. For publicly listed prices, monitoring is generally accepted, but always verify. Don't flood servers. Keep a 2–3 second delay between requests to the same domain. ScrapeGraphAI handles this automatically at the infrastructure level, but still pace your calls.
Monitor your own pages too. Tracking your own product pages through the same pipeline catches pricing errors on your own site before customers do. Set up data quality checks. A price of $0.01 or $99,999 is almost certainly an extraction error. Validate ranges before acting on recommendations:
def is_valid_price(price: float, expected_range=(1.0, 10000.0)) -> bool:
return expected_range[0] <= price <= expected_range[1]Conclusion
Automated price monitoring with ScrapeGraphAI turns a time-consuming manual process into a 24/7 competitive intelligence system. The AI-powered extraction means you're not maintaining a library of brittle CSS selectors — when competitors redesign their pages, the monitor keeps running.
The architecture in this guide is production-ready and can be deployed in a weekend. Start with 5–10 SKUs and your top 2–3 competitors, validate the results, then scale to your full catalog.
Price intelligence is one of the highest-ROI investments a product-based e-commerce business can make. The math is straightforward: better pricing data → better pricing decisions → better margins.
Frequently Asked Questions
Is it legal to scrape competitor prices?
Publicly listed prices on websites are generally considered public information. Monitoring competitor prices for competitive analysis is a common and accepted business practice. However, always review each site's Terms of Service and consult legal counsel for your specific jurisdiction and use case.
How many SKUs can I monitor with ScrapeGraphAI?
The Starter plan ($19/month, 5,000 credits) supports ~200 SKU-competitor pairs per day (hourly checks × 5 competitors). The Growth plan ($85/month, 25,000 credits) handles ~1,000 daily checks. For large catalogs, the Pro plan provides 150,000 credits/month.
What happens when a competitor changes their website layout?
Because ScrapeGraphAI uses AI to understand page content semantically rather than relying on CSS selectors, it automatically adapts to layout changes. This is the core advantage over traditional scrapers that require constant CSS selector maintenance.
Can I monitor prices on Amazon?
Amazon has anti-scraping measures and strict ToS around automated access. For Amazon price data, consider Amazon's Product Advertising API or services like Keepa that specialize in Amazon price history.
How do I handle products where extraction occasionally fails?
Build retry logic with exponential backoff, and skip (rather than delete) snapshots when extraction fails. Your pricing recommendations should require a minimum of 2–3 recent data points before acting:
def get_reliable_price(sku, competitor, min_points=3):
history = get_price_history(sku, competitor, days=1)
if len(history) < min_points:
return None # Not enough data to act on
return history[-1]['price']Related Resources
- AI Agent Web Scraping - Build AI agents that collect data autonomously
- Advance Price Intelligence - Advanced pricing strategies for e-commerce
- Structured Output - Learn about schema-based data extraction with Pydantic