Amazon Price Monitoring: The Complete Web Scraping Guide
Learn how to implement effective price monitoring strategies for Amazon using modern web scraping techniques and tools.
Scraping Amazon Product Data: What I Learned Building a Price Monitor
I've been scraping Amazon for about two years now, and let me tell you - it's been quite the journey. What started as a simple price monitoring tool for my own purchases turned into something much more comprehensive. Here's what I've learned about extracting product data from the world's largest marketplace.
For a complete overview of web scraping fundamentals, check out our Web Scraping 101 guide.
Why I Started Scraping Amazon
Initially, I just wanted to track a few products I was interested in buying. You know how it is - you see something you want, but it's a bit pricey, so you bookmark it and forget about it. Three months later, you remember and find it's even more expensive.
That frustration led me to build a simple price tracker. But once I started pulling data, I realized there was so much more valuable information available:
- Price trends - Not just current prices, but historical data
- Competitor analysis - Who's selling what and at what price
- Market research - Understanding what products are actually popular
- Inventory insights - Stock levels and availability patterns
The data quality on Amazon is actually pretty good compared to other e-commerce sites, which makes it a great place to start if you're new to product scraping.
The ScrapeGraphAI Approach
After trying various scraping methods (and getting blocked more times than I care to admit), I discovered ScrapeGraphAI. It handles a lot of the complexity around modern web scraping, especially for JavaScript-heavy sites like Amazon.
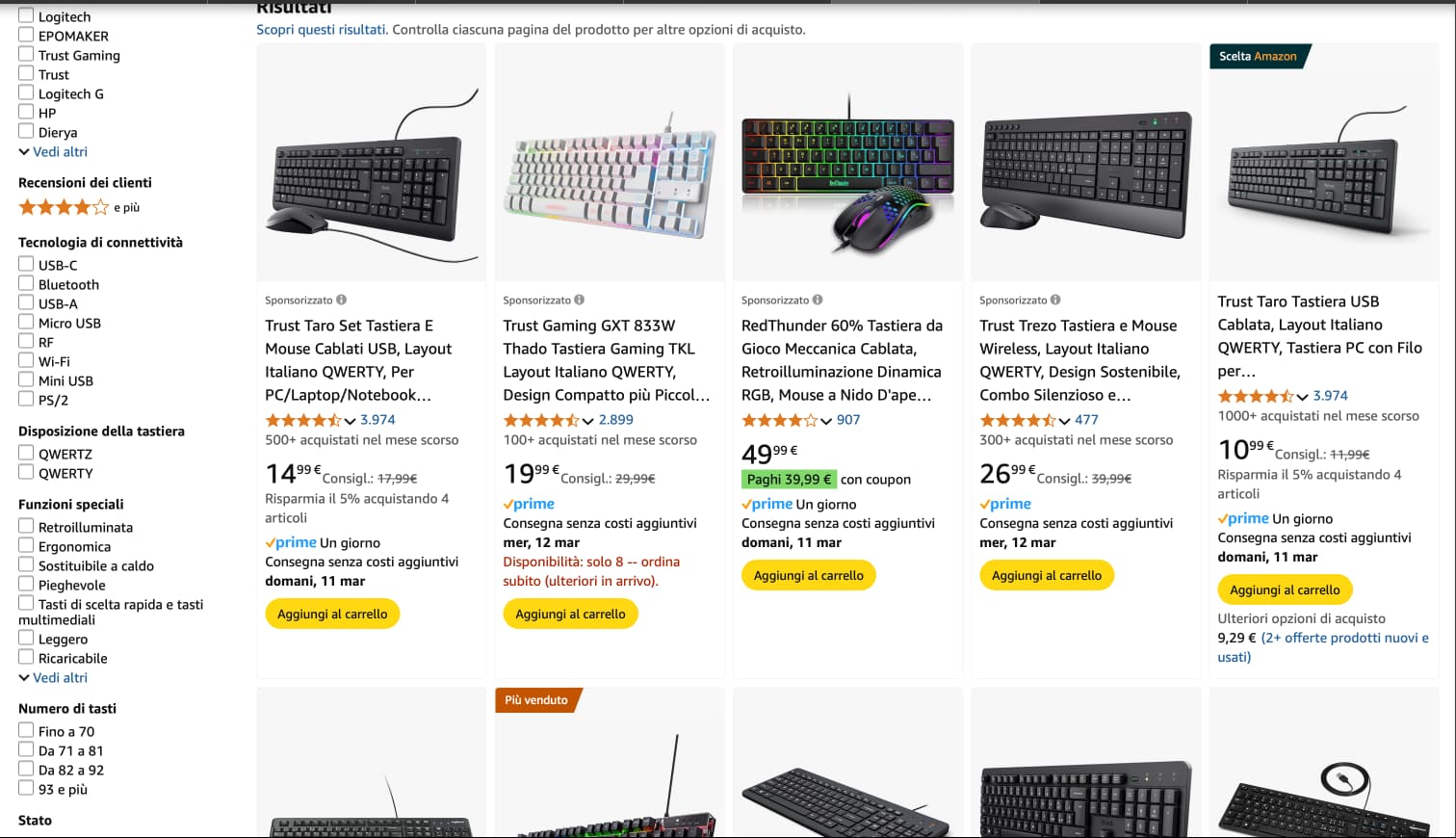
Here's a practical example - let's say you want to monitor keyboard prices on Amazon Italy:
Python Implementation
pythonfrom scrapegraph_py import Client from scrapegraph_py.logger import sgai_logger from pydantic import BaseModel, Field # I always set logging to INFO when developing sgai_logger.set_logging(level="INFO") sgai_client = Client(api_key="sgai-********************") class KeyboardProduct(BaseModel): name: str = Field(..., description="The keyboard name") price: float = Field(..., description="The price in euros") # This is the actual URL I use for testing response = sgai_client.smartscraper( website_url="https://www.amazon.it/s?k=keyboards&__mk_it_IT=AMAZO&crid=MMF6T1GWDMO6&sprefix=keyboars%2Caps%2C119&ref=nb_sb_noss_2", user_prompt="Extract the keyboard name and price from each product listing", output_schema=KeyboardProduct ) print(f"Request ID: {response['request_id']}") print(f"Found {len(response['result'])} products") for product in response['result']: print(f"{product['name']}: EUR{product['price']}") sgai_client.close()
JavaScript Version
javascriptimport { Client } from 'scrapegraph-js'; import { z } from "zod"; const keyboardSchema = z.object({ name: z.string(), price: z.number(), }); const client = new Client("sgai-********************"); async function scrapeKeyboards() { try { const response = await client.smartscraper({ websiteUrl: "https://www.amazon.it/s?k=keyboards&__mk_it_IT=ÅMÅŽÕÑ&crid=MMF6T1GWDMO6&sprefix=keyboars%2Caps%2C119&ref=nb_sb_noss_2", userPrompt: "Extract the keyboard name and price from each product listing", outputSchema: keyboardSchema }); } catch (error) { console.error('Scraping failed:', error); } finally { client.close(); } }
What You'll Get Back
The response structure is pretty clean. Here's what I typically see:
json{ "request_id": "abc123", "result": [ { "name": "Logitech MX Keys S", "price": 91.1 }, { "name": "Razer Ornata V3", "price": 32.78 }, { "name": "EPOMAKER x Aula F75", "price": 24.58 } ] }
Things I Wish I'd Known Earlier
Ready to Scale Your Data Collection?
Join thousands of businesses using ScrapeGrapAI to automate their web scraping needs. Start your journey today with our powerful API.
1. Amazon's Structure Changes
Amazon's HTML structure changes frequently. What worked last month might break today. This is where ScrapeGraphAI really shines - it adapts to these changes automatically.
2. Regional Differences Matter
Amazon.com, Amazon.co.uk, and Amazon.de all have slightly different layouts. If you're scraping multiple regions, test each one separately.
3. Price Formatting is Tricky
Prices come in different formats: "$19.99", "19,99 €", "₹1,999". Having a good parsing strategy is crucial.
4. Rate Limiting is Real
Amazon will block you if you're too aggressive. I learned this the hard way when my IP got temporarily banned. Always respect rate limits.
5. Mobile vs Desktop
Sometimes the mobile version of Amazon has cleaner HTML that's easier to scrape. Worth testing both.
Building a Complete Price Monitor
Here's how I structure my production price monitoring system:
pythonimport time import json from datetime import datetime from scrapegraph_py import Client class AmazonPriceMonitor: def __init__(self, api_key): self.client = Client(api_key=api_key) self.products = [] def add_product(self, product_url, target_price=None): """Add a product to monitor""" self.products.append({ 'url': product_url, 'target_price': target_price, 'price_history': [] }) def check_prices(self): """Check current prices for all monitored products""" for product in self.products: try: response = self.client.smartscraper( website_url=product['url'], user_prompt="Extract the product name and current price", output_schema=ProductSchema ) current_price = response['result']['price'] product['price_history'].append({ 'price': current_price, 'timestamp': datetime.now().isoformat() }) # Check if price dropped below target if product['target_price'] and current_price <= product['target_price']: self.send_alert(product, current_price) except Exception as e: print(f"Error checking {product['url']}: {e}") # Be respectful - don't hammer the server time.sleep(5) def send_alert(self, product, current_price): """Send price alert (implement your notification method)""" # Add your notification logic here (email, Slack, etc.)
Common Gotchas
1. CAPTCHA Pages Sometimes Amazon shows CAPTCHA pages to automated requests. ScrapeGraphAI handles most of these, but it's something to be aware of.
2. Out of Stock Items Handle cases where products are temporarily unavailable. Your parsing needs to account for this.
3. Different Currencies If you're scraping multiple regions, normalize currencies in your data processing.
4. Sponsored Results Amazon mixes sponsored products with organic results. Make sure your scraping logic accounts for this.
Legal and Ethical Considerations
I always check Amazon's robots.txt and terms of service before scraping. Some key points:
- Don't overload their servers
- Respect rate limits
- Don't scrape personal data
- Be transparent about your use case
- Consider using their API when possible
Real-World Performance
In my experience, ScrapeGraphAI can handle about 100-200 product pages per hour without issues. For larger operations, you'd want to implement proper queuing and distributed processing.
I've found that scraping during off-peak hours (early morning EST) tends to be more reliable and faster.
What's Next?
Once you have product data flowing, there are tons of interesting analyses you can do:
- Price trend analysis
- Seasonal pricing patterns
- Competitor pricing strategies
- Market positioning insights
- Stock level monitoring
The key is starting simple and building up. Don't try to scrape everything at once - focus on the specific data you need for your use case.
Wrapping Up
Amazon scraping isn't trivial, but with the right tools and approach, it's definitely manageable. ScrapeGraphAI has made my life much easier by handling the complexities of modern web scraping.
If you're just getting started, I'd recommend:
- Start with a small set of products
- Test thoroughly on different product types
- Build in proper error handling
- Monitor your success rates
- Be respectful of Amazon's resources
The data you can extract from Amazon is incredibly valuable for business intelligence, competitive analysis, and personal use. Just remember to scrape responsibly and always respect the platform's terms of service.
Good luck with your scraping journey!
Related Resources
Want to dive deeper into e-commerce scraping? Check out these guides:
- Web Scraping 101 - Start with the basics
- Amazon Price Monitoring - Build a complete price monitoring system
- JavaScript Web Scraping - Learn browser automation techniques
- AI Agent Web Scraping - Enhance your scraping with AI
- Web Scraping Legality - Stay compliant while scraping