TL;DR
Build a multimodal clothes search engine by scraping Zalando with ScrapeGraphAI, embedding images with Jina CLIP v2, and storing vectors in Qdrant.
- Three-step pipeline — scrape product data, embed images as vectors, store in Qdrant
- ScrapeGraphAI bypasses anti-bot protections — Zalando blocks plain HTTP requests
- Pydantic schemas define extraction targets — brand, name, price, review score, and image URLs
- Jina CLIP v2 enables multimodal search — query with text or images across the same vector space
- Qdrant provides fast vector search — self-hostable with Docker and a built-in UI
Hi there 👋 Today we're building a small demo to search clothes from zalando directly with natural language or images. Our plan of attack is to first scrape them, embed the images using a multimodal model and then store them into a vector search enginge so we can search!
Scraping websites is not an easy task, most of them cannot be easily fetched with an http request and require javascript to be loaded. If we try to make a HTTP request to zalando, we'll be blocked.
import requests
res = requests.get("https://www.zalando.it/jeans-donna")
# we'll get 403
res.status_codeWe need something smarter, scrapegraph is a perfect tool for the job. It can bypass website blockers and allow us to define a pydantic schema to scrape the information we want. It works by loading the website, parsing it and using LLMs to fill our schema with the data within the page.
Once we get the data, we need a way to create vectors to store/search. Since we want to work with images and text, we need the heavy guns. Jina ClipV2 is a wonderful open source model that can represent both images and text as vectors, thus it's a perfect pick for the task.
Finally, we need to save our juicy vectors somewhere. Qdrant is my go-to vector search engine, you can self host it with docker and it comes with a handy ui. It supports different vector quantization techniques, so we can squeeze a lot of performance!
So, to recap. Our plan of attack looks something like:
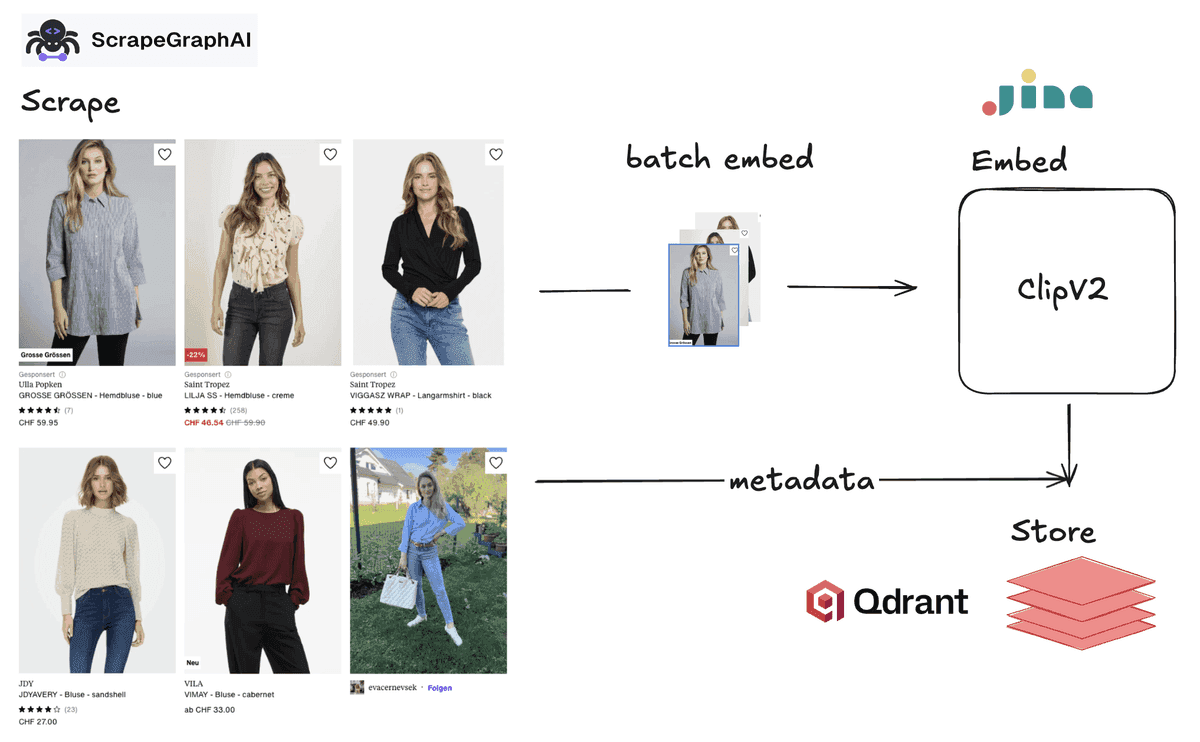
- Scrape with Scrapegraph
- Embed with Jina ClipV2
- Store with Qdrant
Let's get started!
Setting it up
We'll need a bunch of packages. I am using uv, so we'll stick with it. You can init your project using
!uv init
!uv add python-dotenv scrapegraph-py aiofiles sentence-transformers qdrant-clientOr if you prefer pip
pip install python-dotenv scrapegraph-py aiofiles sentence-transformers qdrant-client
Scraping
First of all, head over to ScrapeGraphAI and get your API key. Create a .env file and put it inside
GAI_API_KEY="YOUR_API_KEY"
Then we load it
from dotenv import load_dotenv
import os
load_dotenv()
SGAI_API_KEY = os.getenv("SGAI_API_KEY")Now, we need to define the data we want. Each article/item on the website looks like:

We have a brand, name, description, price, image, review, etc.
In order to tell scrapegraph what we want to extract, we have to define a couple of pydantic schemas. Since a page contains multiple items, we'll create an ArticleModel for the single article, and ArticlesModel containing an array of them.
We can add description to make sure we guide the LLM into extracting the correct info.
from pydantic import BaseModel, Field
from typing import Optional
import asyncio
class ArticleModel(BaseModel):
name: str = Field(description="Name of the article")
brand: str = Field(description="Brand of the article")
description: str = Field(description="Description of the article")
price: float = Field(description="Price of the article")
review_score: float = Field(description="Review score of the article, out of five.")
url: str = Field(description="Article url")
image_url: Optional[str]= Field(description="Article's image url")
class ArticlesModel(BaseModel):
articles: list[ArticleModel] = Field(description="Articles on the page, only the ones with price, review and image. Discard the others")Now, the fun part. We'll store our scraped data locally into a .jsonl file. We'll also add a user_prompt to guide scrapegraph even further. Since the scraping process is heavily I/O bound, we'll use their AsyncClient so we can fire a lot of them at once.
Let's import everything and define our variables.
from time import perf_counter
# let's use async
from scrapegraph_py import AsyncScrapeGraphAI
# let's use async to write to the file as well
import aiofiles
import json
import asyncio
import os
JSON_PATH = "scrape.jsonl"
# how many scraping requests to fire at once
BATCH_SIZE = 8
# how many pages per category
MAX_PAGES = 100
# the user prompt to send to scrapegraph along the pydantic schemas
user_prompt = "Extract ONLY the articles in the page with price, review and image url. Discard all the others."To start scraping, we can use the extract method. Let's quickly see it
# defining our client
sgai = AsyncScrapeGraphAI()
# get our zalando link for women's jeans - sorry I am Italian xD
url = "https://www.zalando.it/jeans-donna/"
# get the response
response = await sgai.extract(
user_prompt,
url=url,
schema=ArticlesModel.model_json_schema(),
)
response.data.json_data["articles"][0:2]💬 2025-10-08 10:23:24,101 🔑 Initializing AsyncClient
💬 2025-10-08 10:23:24,101 ✅ AsyncClient initialized successfully
💬 2025-10-08 10:23:24,101 🔍 Starting extract request
💬 2025-10-08 10:23:24,104 🚀 Making POST request to https://v2-api.scrapegraphai.com/api/extract (Attempt 1/3)
💬 2025-10-08 10:23:34,194 ✅ Request completed successfully: POST https://v2-api.scrapegraphai.com/api/extract
💬 2025-10-08 10:23:34,196 ✨ Smartscraper request completed successfully
[{'name': 'Calvin Klein Jeans MID RISE - Jeans a sigaretta - indigo channel',
'brand': 'Calvin Klein Jeans',
'description': 'No content available',
'price': 54.99,
'review_score': 0,
'url': 'https://www.zalando.it/calvin-klein-jeans-mid-rise-jeans-a-sigaretta-indigo-channel-c1821n0wb-k11.html',
'image_url': 'https://img01.ztat.net/article/spp-media-p1/391e37f99e42468193efe13676cb98f4/7f2e068eb2a24d3aa5edadce0e9fd461.jpg?imwidth=300'},
{'name': 'GAP BAGGY DYLAN - Wide Leg - light indigo',
'brand': 'GAP',
'description': 'No content available',
'price': 42.49,
'review_score': 0,
'url': 'https://www.zalando.it/gap-baggy-dylan-jeans-baggy-light-indigo-gp021n0ih-k11.html',
'image_url': 'https://img01.ztat.net/article/spp-media-p1/0a09f06a933c4714bb81369f858c9cde/8c619d57599f43ee9577b67e5c8ee170.jpg?imwidth=300'}]
Okay, let's make our code bulletproof. We need a function to save our data to disk as JSONL.
async def save(result: dict):
async with aiofiles.open(JSON_PATH, 'a') as f:
await f.write(json.dumps(result) + '\n')Let's then call extract, passing the sgai client and the url.
async def scrape_and_save(sgai: AsyncScrapeGraphAI, url: str):
start = perf_counter()
print(f"Scraping url={url}")
response = await sgai.extract(
user_prompt,
url=url,
schema=ArticlesModel.model_json_schema(),
)
if response.status == "success":
await save(response.data.json_data)
print(f"Took {perf_counter() - start:.2f}s")Finally, putting it all together. We'll scrape women's jeans and t-shirt tops. We'll check first if JSON_PATH exists, and if so we'll assume we had already scraped.
async def main():
get_urls = [
lambda page: f"https://www.zalando.it/jeans-donna/?p={page}",
lambda page: f"https://www.zalando.it/t-shirt-top-donna/?p={page}"
]
should_scrape = not os.path.exists(JSON_PATH)
if not should_scrape:
print("jsonl file exists, assuming we had scrape already. Quitting ...")
return
async with AsyncScrapeGraphAI() as sgai:
for get_url in get_urls:
for i in range(1, MAX_PAGES + 1, BATCH_SIZE):
pages = list(range(i, min(i + BATCH_SIZE, MAX_PAGES + 1)))
tasks = [scrape_and_save(sgai, get_url(page)) for page in pages]
await asyncio.gather(*tasks)I've done it already, you can find the jsonl here
# we'll take some minutes
await main()💬 2025-10-08 10:23:34,214 jsonl file exists, assuming we had scrape already. Quitting ...
And then you have it, each line is a page scraped!
with open(JSON_PATH, "r") as f:
for line in f.readlines():
data = json.loads(line)
break
data["articles"][0]{'name': 'PULL&BEAR BAGGY - Jeans baggy - white',
'brand': 'PULL&BEAR',
'description': 'Cropped top bianco senza maniche abbinato a pantaloni bianchi a gamba larga, con tasche frontali e chiusura a bottone. Sandali piatti marroni con borchie.',
'price': 35.99,
'review_score': 0,
'url': 'https://www.zalando.it/pullandbear-jeans-bootcut-white-puc21n0rs-a11.html',
'image_url': 'https://img01.ztat.net/article/spp-media-p1/ff33dd220e7c4827ba1b8be760e6de7c/b9ca1dcb64b04fa98b0e0d5fa38fff14.jpg?imwidth=300'}
Embedding
The heavy part is done, now we need to embed each image. We'll convert the images into numerical vectors so we can perform similarity searches and find visually similar products. Recall, our pydantic model has an .image_url field that holds the link to the image for an article on Zalando.
data["articles"][0]["image_url"]'https://img01.ztat.net/article/spp-media-p1/ff33dd220e7c4827ba1b8be760e6de7c/b9ca1dcb64b04fa98b0e0d5fa38fff14.jpg?imwidth=300'
Let's do some good programming, limiting the amount of data we have in memory each time. We'll batch process the articles, so we can load one line of the JSONL at a time. This can be done in Python with a generator.
def get_articles_from_disk():
with open(JSON_PATH, "r") as f:
for line in f.readlines():
data = json.loads(line)
yield data["articles"]
articles_gen = get_articles_from_disk()We'll use the wonderful ClipV2 model made by Jina to create vectors for our images. The model has matryoshka representation, allowing (quoting from their blog post) to "truncate the output dimensions of both text and image embeddings from 1024 down to 64, reducing storage and processing overhead while maintaining strong performance." We'll use 512 dimensions and use the model with sentence_transformers.
from sentence_transformers import SentenceTransformer
EMBEDDING_SIZE = 512
# initialize the model - will take some time to download it
model = SentenceTransformer(
"jinaai/jina-clip-v2", trust_remote_code=True, truncate_dim=EMBEDDING_SIZE
)Then, we can just pass an image URL to get the embeddings. We also normalize them since we will use cosine similarity to perform search later.
image_embeddings = model.encode(data["articles"][0]["image_url"], normalize_embeddings=True)
image_embeddings[0:10]array([-0.12898703, 0.13965721, -0.13102548, 0.09683744, -0.02695999,
0.04831071, -0.15391393, 0.01224686, -0.10350402, 0.05697947],
dtype=float32)
Storing
Now we need somewhere to store them. Qdrant is a perfect solution, and we'll run it locally with Docker and Docker Compose.
Assuming you have it on your system, we create a docker-compose.yml file.
version: "3.8"
services:
qdrant:
image: qdrant/qdrant:latest
ports:
- "6333:6333"
- "6334:6334"
volumes:
- ./qdrant_storage:/qdrant/storage:z
Then, simply
docker compose up -dThis will spin up Qdrant, which also comes with a very nice UI accessible at http://localhost:6333/dashboard#/collections where you can see your data.
Initialize the database
We need to create a collection. We'll also use quantization to speed things up and save storage. You can read more in the Qdrant documentation about this feature. We'll use cosine similarity for search and keep the quantized vectors in RAM to speed things up as well.
from qdrant_client import QdrantClient, models
import numpy as np
QDRANT_COLLECTION_NAME = "clothes"
QDRANT_URL = "http://localhost:6333"
# defining qdrant client
client = QdrantClient(url=QDRANT_URL)
# checking if we haven't created the collection already
if not client.collection_exists(QDRANT_COLLECTION_NAME):
print(f"{QDRANT_COLLECTION_NAME} created!")
client.create_collection(
collection_name=QDRANT_COLLECTION_NAME,
vectors_config=models.VectorParams(
size=EMBEDDING_SIZE, distance=models.Distance.COSINE, on_disk=True
),
quantization_config=models.ScalarQuantization(
scalar=models.ScalarQuantizationConfig(
type=models.ScalarType.INT8,
quantile=0.99,
always_ram=True,
),
),
)Unclosed client session
client_session: <aiohttp.client.ClientSession object at 0x10d05d010>
Unclosed connector
connections: ['deque([(<aiohttp.client_proto.ResponseHandler object at 0x10d0319d0>, 12896.416191291)])']
connector: <aiohttp.connector.TCPConnector object at 0x10d05cc20>
clothes created!
We want to process our data in batches to efficiently utilize both the embedding model and the network connection to Qdrant.
import uuid
from tqdm.autonotebook import tqdm
BATCH_SIZE = 8
def embed_articles(data: dict) -> np.array:
image_urls = [el["image_url"] for el in data]
image_embeddings = model.encode(
image_urls, normalize_embeddings=True
)
return image_embeddings Inserting into the database
Then, we can create a function to insert them into the database. We'll also store the dictionary itself by passing it to the payload parameter.
def insert_articles_in_db(batch: list[dict], embeddings: np.array):
client.upsert(
collection_name=QDRANT_COLLECTION_NAME,
points=[
models.PointStruct(
id=str(uuid.uuid4()),
vector=vector,
payload=payload
)
for payload, vector in zip(batch, embeddings)
],
)Putting it all together, we'll check if we have points in the collection; if so, we'll assume we've already run it.
def store_to_vector_db():
shold_insert = client.count(QDRANT_COLLECTION_NAME).count == 0
if not shold_insert:
print(f"Collection={QDRANT_COLLECTION_NAME} not empty. Exiting ...")
return
with tqdm(articles_gen, desc="Article Collections", position=0) as pbar_collections:
for articles in pbar_collections:
batches = list(range(0, len(articles), BATCH_SIZE))
with tqdm(batches, desc="Processing Batches", position=1, leave=False) as
pbar_batches:
for i in pbar_batches:
batch = articles[i:i + BATCH_SIZE]
embeddings = embed_articles(batch)
insert_articles_in_db(batch, embeddings)
store_to_vector_db()
Collection=clothes not empty. Exiting ...
We can head over the qdrant ui to see the data
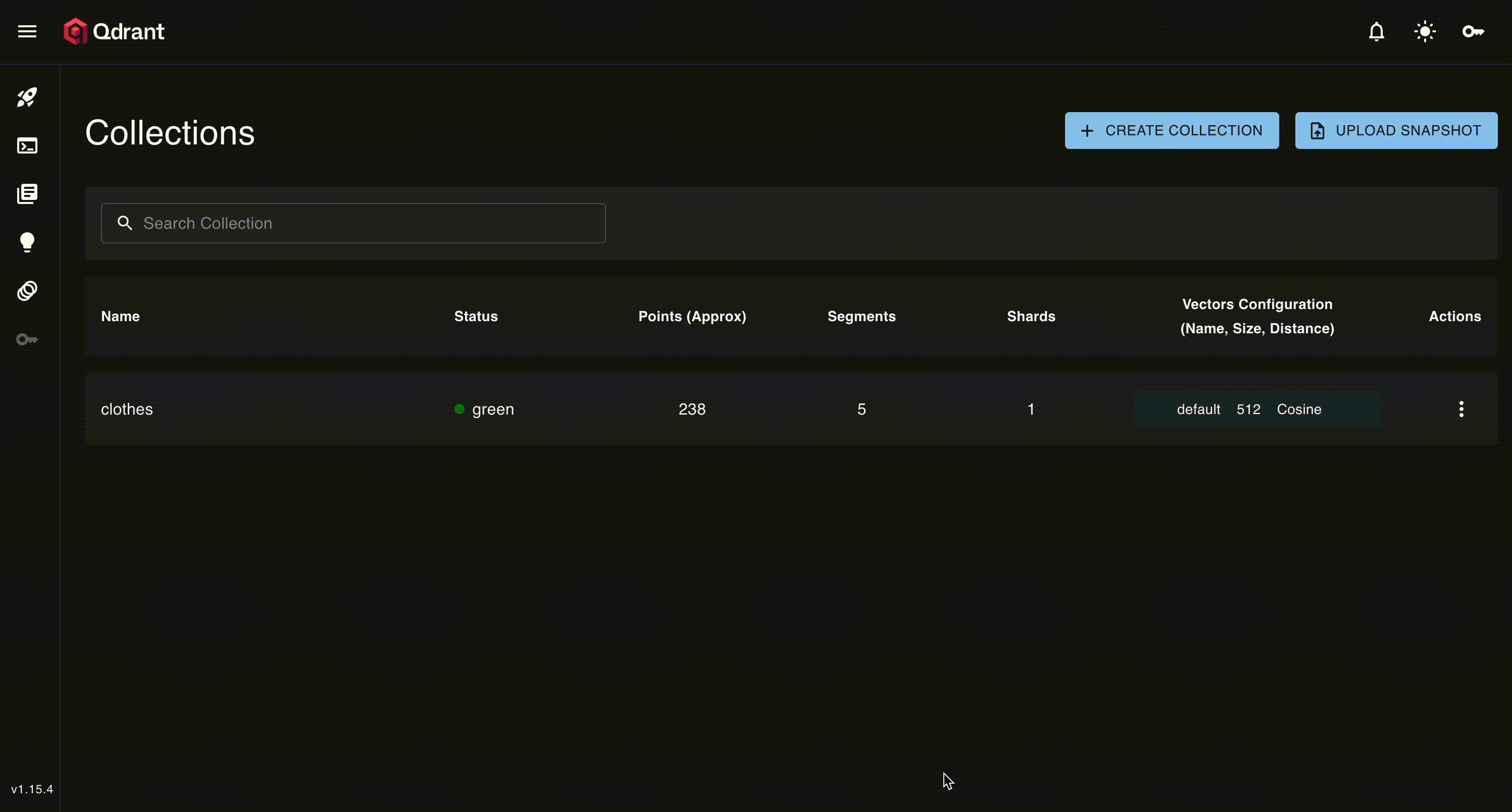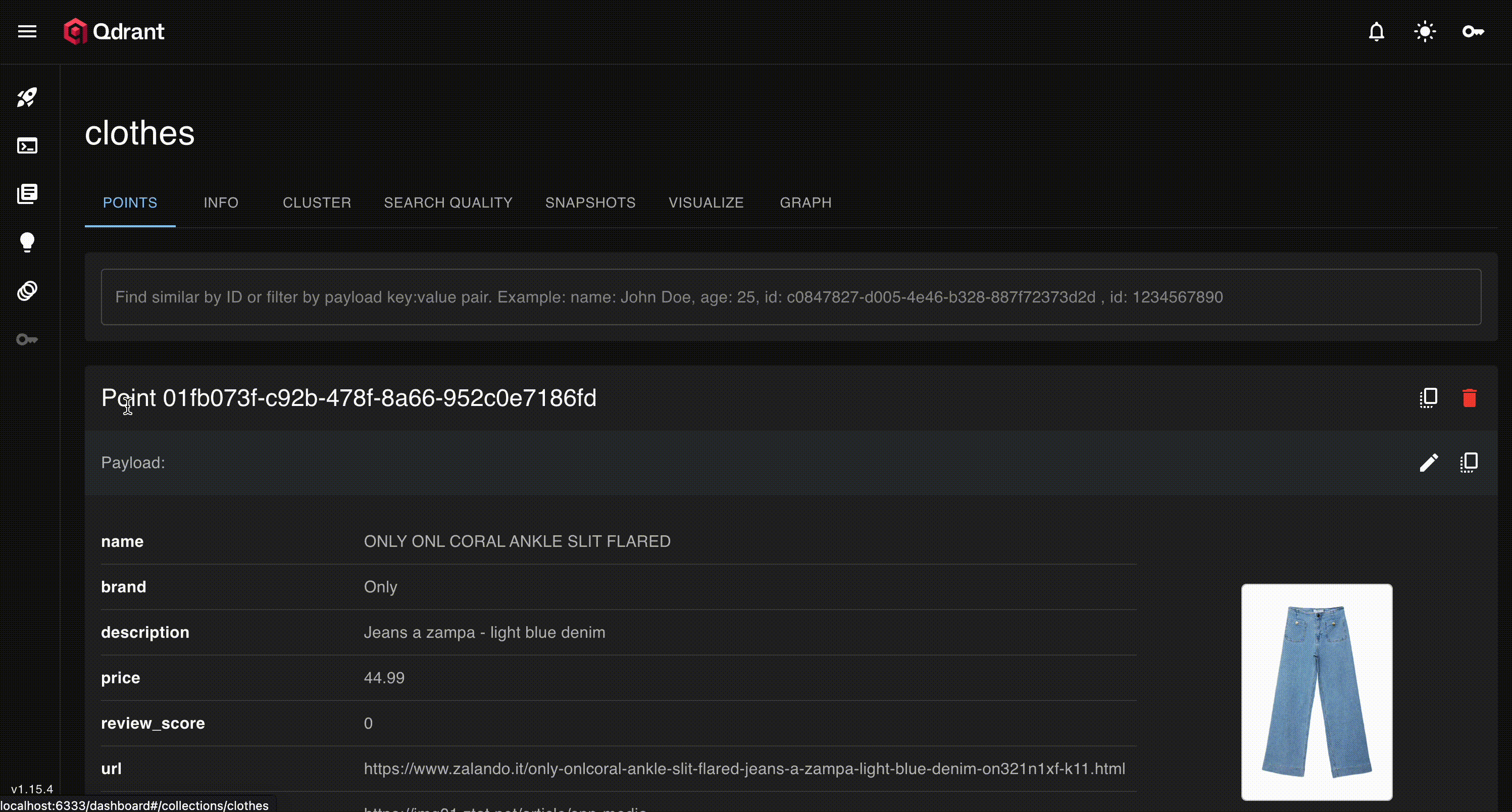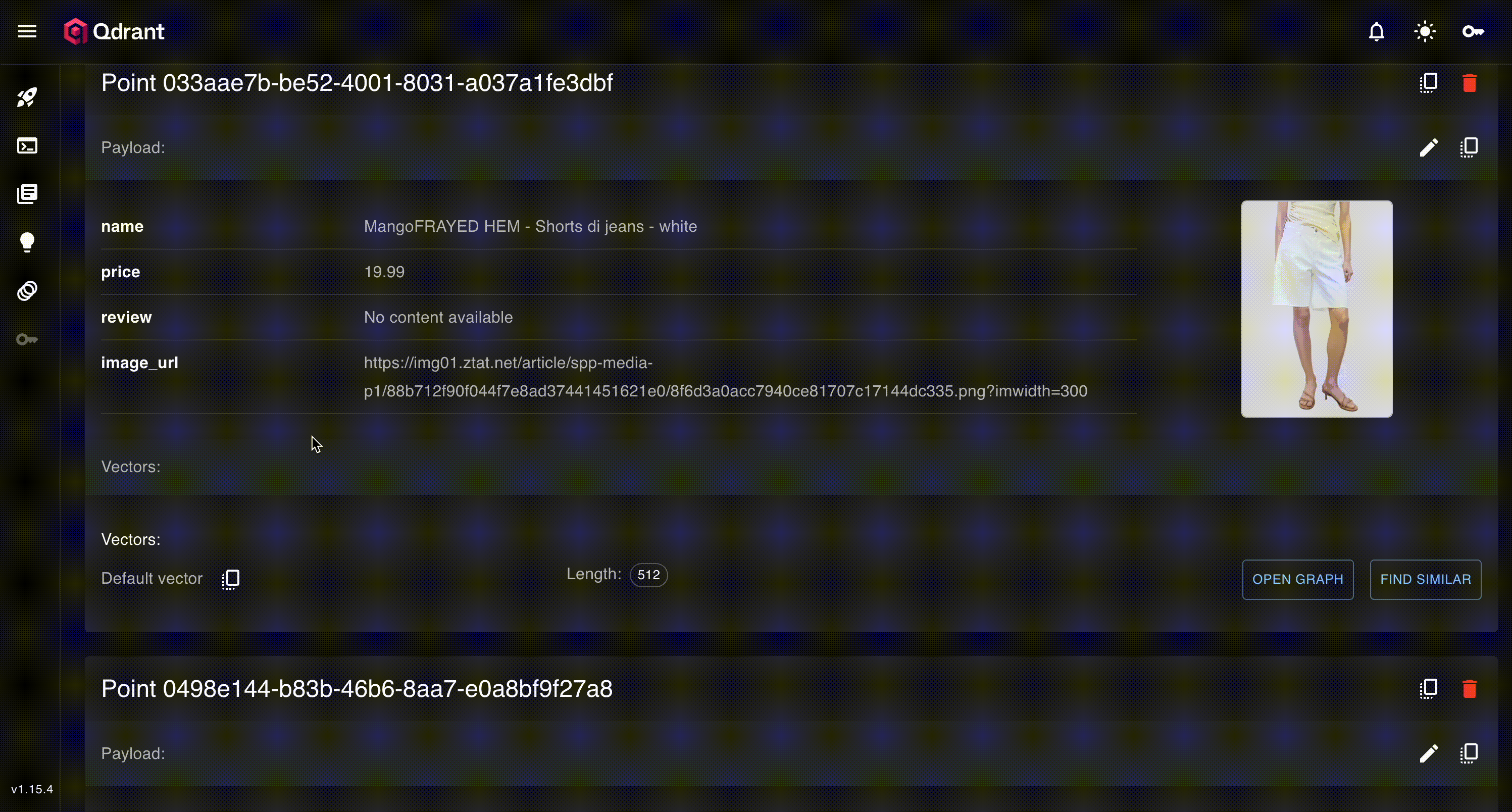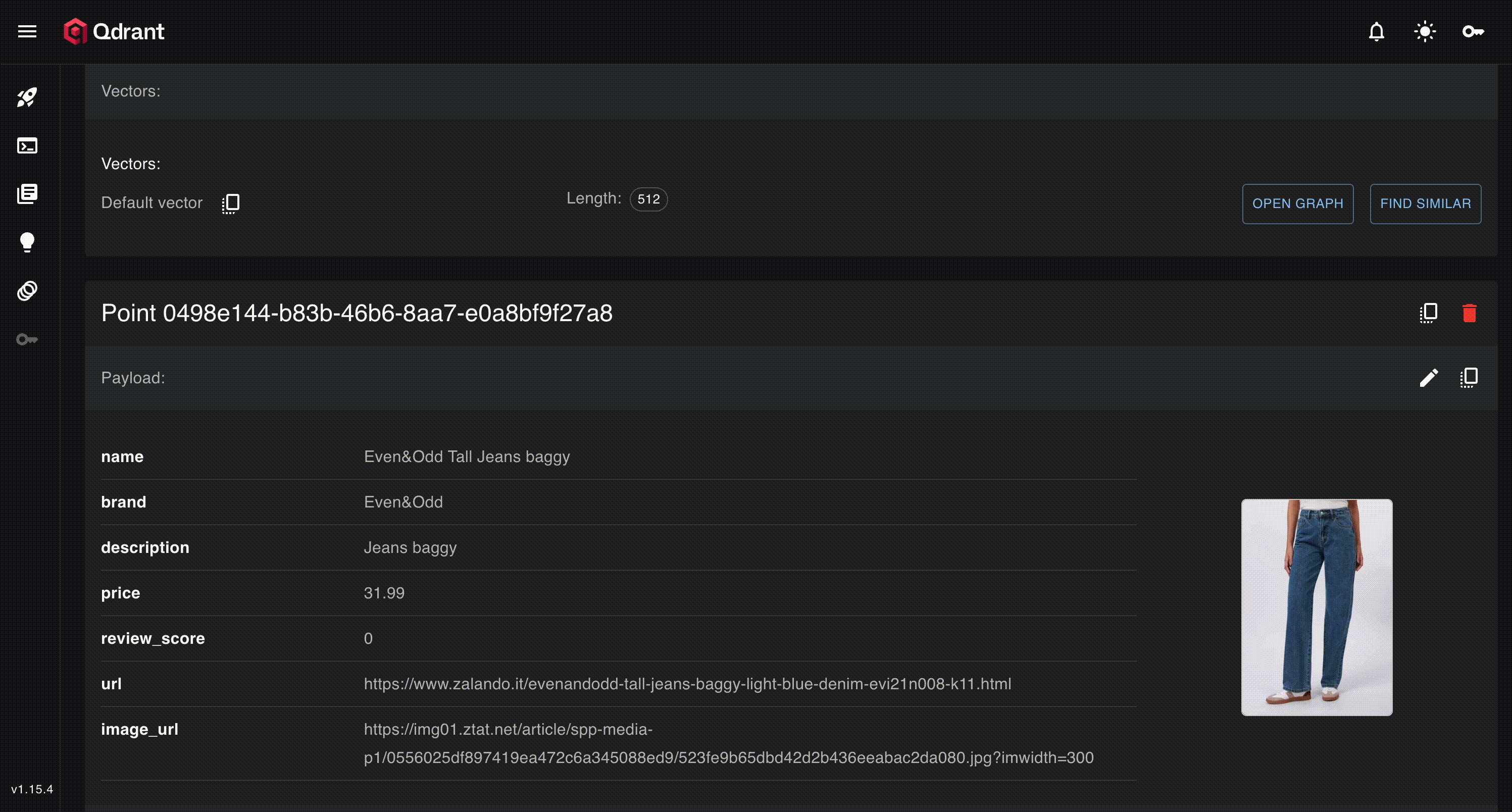
It also comes with a very cool dimension reduction tab to explore our embeddings!

Searching
We can now search 🥳! With either a text query or an image
query = 'red pants'
# call the model to embed the query
query_embeddings = model.encode(
query, prompt_name='retrieval.query', normalize_embeddings=True
)
# getting results
res = client.search(
collection_name=QDRANT_COLLECTION_NAME,
query_vector=query_embeddings.tolist(),
limit=4,
)/var/folders/st/ghlgjhss71l6tm_gvh7nzcv80000gp/T/ipykernel_41659/1688051610.py:8: DeprecationWarning: `search` method is deprecated and will be removed in the future. Use `query_points` instead.
res = client.search(
Let's define a function to show the results
from IPython.display import display, HTML
def show_images(res):
html = "<div style='display:grid;grid-template-columns:repeat(4,1fr);gap:10px;'>"
for result in res:
html += f"<img src='{result.payload['image_url']}'
style='width:300px;height:auto;object-fit:cover;border:1px solid #ddd;'>"
html += "</div>"
display(HTML(html))
show_images(res)

We're seeing mixed results here—both red pants and red tops appear in our outputs. The issue stems from how we process the images. Most product photos show nearly full-body shots of the model, so when we have a jeans item, for example, the image captures both the jeans and the upper body. We'll leave it as a take-home exercise for the reader to use a segmentation model to isolate the actual article from the model, crop it, and then embed it.
Since ClipV2 is multimodal, we can also use an image.
# or using either a pil image or a url
from IPython.display import Image, display
image_url = "https://d1fufvy4xao6k9.cloudfront.net/images/landings/43/shirts-mob-1.jpg"
# call the model to embed the query
query_embeddings = model.encode(
image_url, normalize_embeddings=True
)
# getting results
res = client.search(
collection_name=QDRANT_COLLECTION_NAME,
query_vector=query_embeddings.tolist(),
limit=4,
)
Image(url=image_url, width=400)
show_images(res)
Conclusion
So we've shown how to scrape, embed, and search using both text and image items from Zalando. ScrapeGraph-AI is pretty neat - it handles the scraping automatically without needing to mess with selectors. Jina CLIP v2 works really well for combining text and images in the same search space. And Qdrant is solid - fast, easy to use, and that dashboard is actually quite helpful for exploring your data.
We could expand this further by scraping more data and implementing a re-ranker to surface results that are truly relevant to the query - but I'll leave that to you! :)
Authors: Francesco Zuppichini and Neil Kanungo
LinkedIn: Francesco Zuppichini | Neil Kanungo